大数据文摘作品,转载具体要求见文末
作者|Aileen 翻译|任杰 校对|霍静
◆◆◆
导读
初为人父人母,最大的体会必须是:缺觉!喂奶换尿布,孩子一夜醒来好几次,没把小宝宝哄睡,却把自己哄睡了,那时候你的内心一定是崩溃的。
国外一个缺觉的父亲实在受够了他的双胞胎宝宝,联合他的妻子,统计了两个娃的睡眠及喂养时间数据等,用机器学习分析预测,总结并掌握两个孩子的作息规律,科学的育儿方法让他们伺候好孩子的同时,又将孩子对自己的睡眠影响降到最低,真是太机智了。技术咖拯救睡眠啊!
接下来就让我们看看这对夫妻是如何收集数据、并利用机器学习分析数据的,或许年轻的我们可以学一手。
这样看来机器学习和数据决策其实并没有那么高高在上,可能也可以帮我们解决一些生活中的有趣问题。
◆◆◆
前言
一个月前,我试着用A / B测试我们那对双胞胎,看看怎样不同的“治疗”或输入参数会造成较久的睡眠,当然这由我们自己来完成。我发现睡眠模式相当不稳定,并没有找到促进睡眠相关的东西。随着时间的推移,他们更大程度上倾向于自然醒。然而,现在他们已经四个月大了,他们已经开始普遍但是很少讨论的睡眠颠倒(Sleep Regression)。我又一次发现自己渴望获得更多的睡眠。我先前投的文章中确实有一个评论说,“无论多么渴望睡更多,我都会努力去找,我能找到对于睡眠有用的东西吗”?嘿嘿,我找到了。从此,我转而关注另一项计算机科技:机器学习。
机器学习是一个计算机科学的领域,提供 “教”计算机或程序的方式,而不需要给他们一些分散的指令集。在正常编程中,我会让计算机按顺序执行一列命令,按逻辑基于输入的方法来做决策,不过这些程序永远都不会离开已定义好的轨迹。尽管这听起来比它实际上运行的方式更像终结者(Terminator),但是机器学习可以接受人拿给的用于“学习”的数据,以此作为预测的基础。虽然这在整个科技行业变得越来越流行,而AI主要被用于浏览购买行为和推荐,也许最有趣的是,分类和识别照片和画作,这大多是谷歌在做。我没有找到什么例子用于做家长带小孩。
多亏我的妻子是会计背景,还有我们的A型人格,我们详细记录了两个男孩的进食和睡眠行为。还记得这个表格吗?
◆◆◆
“大数据”,毫不夸张的讲
使用这些数据,我开始寻找输入参数的最优组合,在这个例子中,我关注食物总消耗、最后喂食时间和最后喂量,来决定什么情况会导致男孩的最久时间睡眠。最重要的是我可以让计算机做艰苦的工作。另外,我们这组模式有两倍的数据,因为很明显我们有两个男孩。
有几个可用的巨大机器学习库,他们跨编程语言。虽然我主要使用Java和Javascript工作,我选择了Python库sklearn,因为我熟悉Python以及这个灵活的脚本语言可以说是近乎完美的应用。有许多对这个库和文档极好的教程。
如果感兴趣,你可以在github上找到我的代码。
把我们从电子表格收集的数据导出来,我提取了过去一个月的数据点。因为婴儿正经历快速的成长发育变化,我觉得一个月的数据乘以2个婴儿,是一种对近因效应较好的平衡,而且数据足够用于做预测了。
◆◆◆
放在一起进行编码
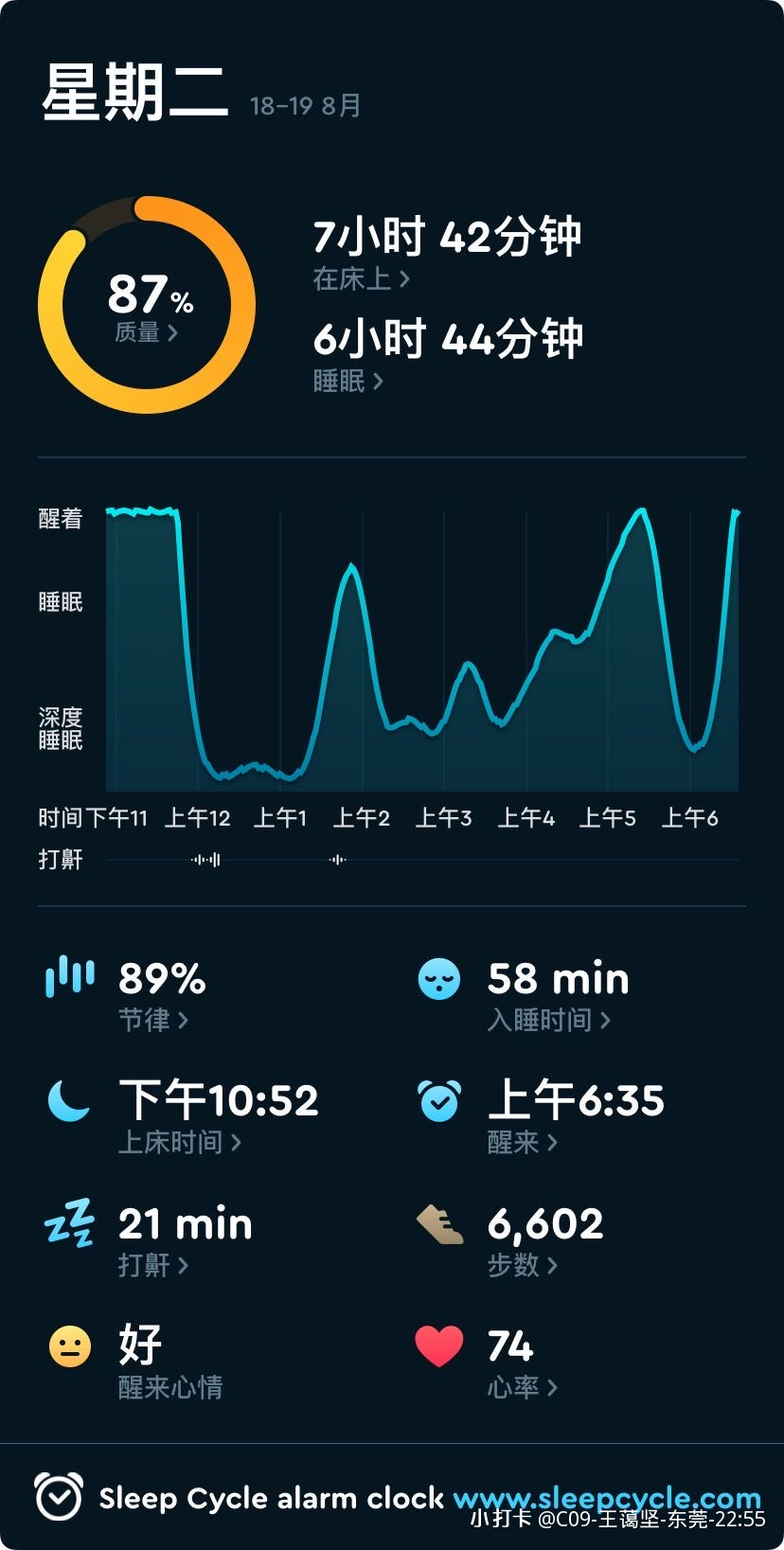
我也得到了一些有趣的统计值,包括:平均每天我们喂食两男孩(各)27.5盎司,通常让他们在睡觉在7:25睡觉,睡前喂他们5.22盎司,它们平均睡9个小时。结果发现男孩75%的情况睡超过10小时。不赖的发现。但我知道我们还有一些工作可以改进。
总喂食
最后喂食时间
最后喂食量
睡眠时间(小时)
次数
62
62
62
62
均值
27.491935
7.455645
5.225806
9.084677
标准差
2.001008
0.331181
0.857357
1.726092
最小值
24.000000
6.750000

2.000000
3.500000
25%
26.000000
7.250000
5.000000
8.000000
50%
27.000000
7.375000
5.000000
9.000000
75%
29.000000
7.687500
6.000000
10.187500
最大值
32.000000
8.500000
7.000000
13.500000
采用这些数据,我能够画出对于睡眠时间的每个参数。
你可以看出数据间已经没有很强的相关性,至少多数不存在线性关系。最具线性特征的关系,还有很多离群点的,要属总进食量和睡眠小时之间的关系了。奇怪的是婴儿吃得多反而睡得少了。
有许多不同类型的机器学习算法。这些主要分为线性和非线性两种类型。我用了六种使用相当广泛的算法运行这组数据,看看每个能到的准确程度。以下是结果。
Logistic Regression: 0.303333 (0.211056)
Linear Discriminant Analysis: 0.376667 (0.157797)
K Neighbors Classifier: 0.286667 (0.073333)
Decision Tree Classifier: 0.356667 (0.196667)
GaussianNB: 0.183333 (0.076376)
Support Vector Machine: 0.410000 (0.200028)
注:每种算法的准确程度,括号中的为标准差,或者采用一个形象的图表
在这里你可以看到,支持向量机算法在这些数据上完成的明显最好,虽然变化范围较宽,均值并不比其他的算法强很多。这些方法用于预测甚至没有一个超过50%的(均值)。这完全是由于数据的伪随机性质。即使有这样的结果,我决定继续尝试,希望能深入有更多新奇的发现。
采用支持向量机,我用输入的数据训练算法。用了这个,当我们哄孩子们上床,基于一天的食物量,以及睡前前最后一餐的量,我现在就可以预测出他们能睡多久。例如,给他们28盎司,哄他们7点上床,最后一餐喂6盎司,将造成一个比较差的8小时的睡眠。
◆◆◆
结论
用目前训练出的算法,某种程度上,我可以预测将会得到多久的睡眠。更重要的是,我可以从箱型图(Box Plot)中,6种流行的算法性能趋线,看出他们的表现。并且试着优化,明白怎样类型的行为可以造成更久的睡眠。一种反常规的现象是,早些躺下,吃更少的食物,实际上一整天的睡眠时间却增加了。这可能是由于很多因素导致的,但我的理论是,吃得少那补充的就少,胃收缩的也就减少,因此睡眠也就更安稳。有多少次你是狼吞虎咽,然后奇怪的是在半夜饿醒了?
很不幸,正如用A/B测试一样,没有一种个体输入对睡眠似乎是直接的。我想如果真的有人已经发现了,能挣数百万。综上所述,机器学习可以找到变量之间一些像这些的趋势和关联,从而得到比A/B测验或者“试误法”(trial and error)更好、更准确的结果,仍然结果还差得很远呢。从这组数据集,最多可以得到41%的预测准确率。这意味着结果往往是错误的。由于频繁的发育变化,还有男孩之间的差异,很难在他们之间应用数据。再次申明,样本量大一点是有帮助的,但我们不打算很快要三胞胎。
尽管如此,这些结果总比没有好,帮助论证了机器学习和数据科学领域的许诺。比起依据直觉,我更喜欢靠数据来决策,和这些证实我猜测的数据,只会让我对我们的育儿方法感觉更好。
原文链接:
关 于 转 载 如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘|bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:zz@bigdatadigest.cn。
◆ ◆ ◆
志愿者介绍
大数据文摘后台回复“志愿者”,了解如何加入我们







