56786!#27594/1摘要本体的构建是影响语义RG成功与否的重要因素之一。本文借鉴机器学习以及自然语言处理等技术成果尝试半自动构建本体,以专业研究论文为研究语料,采用#CTAE文本表达法从语料中抽取关键概念,计算主题度获取领域概念。利用改进的层次聚类算法对领域概念进行聚类以获取其等级体系,采用句法分析与统计相结合的方法从语料中获取可能的主、谓、宾模式为领域关系提供参考,并以农业史为例,设计开发了一个领域本体半自动构建实验系统,文中重点介绍了本体构建中概念的获取、等级关系、领域关系的构建以及形式化处理等关键技术的实现过程。关键词领域本体半自动构建概念抽取等级关系领域关系主谓宾模式6G3BHEHL234&3%"5FGQKLG@GHLQQXA=HV>YWGAEXB=H=VBGQ,ZFBMFAGUKBAGWEQXEHLGEQYGHVBHGEHLE[=BLEHMEMUKBQBXB=XX>GHGZGXE\GXFMFXFEXM=HQXAKMXXFG=HX=VYEKX=DEXBME>>Y,ZFBMFEXXGD@XDGXF=LXFEXG]XAGDGGHGWBMBE>EMUKBQBXB=HXEQ\ZEQXFZBXFDEMFBHG>GEAHBHVXGMFHBUKGXFG=HXGMX,BHM>KLBHVL=DEB=HMG@XEMUKBQBXB=H,XE]=H=DY=VHBXB=H,H=HCXE]=H=DYAG>EXBEHL=HX=>=VYDE>B^EXB=HLGQMAB@XBGAEL=@XHCLBMXB=HEA"GVDGHXEXB=HMFHBUKGQSEQGEMUKBL=DEBHMEHLBLEX=HMG@XQ,XE\GXFGDGXF=LSEQBHXFH,G]XAEMXMX,@AGLBMEXGHXGHMGQ5FBQXABEHV>LEXEMEEQXFXAB@>GX6A(%8#L=DEBHHX=>=VY,QDBCEKX=DEXBMXB=H,M=HMG@XG]XAEMXB=H,FBGAEAMFYAG>EXB=H,"C_C/D=LG语义RGS很大程度上依赖形式化本体来组织机器可理解和传输的数据,毫无疑问本体可以为语义RGS成功增值。
本体是语义RGS的基础,因此关于本体构建的研究成为目前本体领域的研究重点之一。目前本体主要还是依赖于手工构建,然而手工构建本体是一项工作量巨大并且异常繁杂的任务。利用人工智能领域所取得的成果,半自动或半半自收稿日期:)%%+作者简介:何琳,女,$,*%年生,博士,南京农业大学信息管理系讲师,主要研究方向:信息检索。7CDEB>:FG>BH本研究得到《中国农业科技遗产数字化保护与利用研究》(科技部社会公益专项基金项目子课题)%%(:!NO.%)*)和南农业大学青年创新基金(9)%%+)+)的资助。万方数据领域中许多机器学习的方法被改进应用到的学习中,实现的半半自动或半自动构建,可以在很大程度上加快构建进程,节省很多的人力和时间。本文主要借鉴机器学习、自然语言处理中的技术成果以及情报学中的方法论尝试半自动构建本体,设计并开发了一个领域本体半自动构建系统,以提高本体生成的效率。相关研究本体学习),-.&/&*)是一个新兴的领域,旨在利用机器学习技术帮助知识工程师自动构建本体,主要可以借鉴词性标注、词义消歧、短语切分等自然语言处理技术以及聚类技术、决策树分类等机器统计学习技术。这方面主要的成果有:术中的有关技术尝试半自动构建领域本体,从语料中抽取领域概念,通过聚类技术、统计分析技术以及句法分析等技术构建面向语义信息检索的领域本体。
系统的总体设计如图领域本体半自动构建系统模块图($)候选概念获取模块:候选概念获取模块的主!"235675(5--.8.9:;,&要功能是利用WHN.->文本表达法从领域语料库中报道了自然语言处理技术用于本体学习(#)领域概念筛选模块:领域概念筛选模块的主抽取代表概念的重要词汇,并通过一些通用的顶级本体来消除歧义以确定最后的概念词。要功能是对领域概念候选集进行主题归属度计算,筛选出该领域的核心概念,同时采用基于模式匹配由领域专家提供少数高度概括本体的方法抽取语料中的同义词对主题概念进行词形领域的“核心词汇”,从上利用这些“核心词汇”搜索相关文档,利用模式匹配从中抽取相关概念和概念关系。G(,.*HIA,用企业网的数据构建保险业本体,通过领域词典获得领域概念,使用领域的自然语言文本语料来剔除启发规则算法中获得的非领域词汇。通过统计学习算法和模式匹配算法的多策略学习算法来计算概念之间的关系。董慧提出采用基于统计模式抽词,基于奇异值分解从词H文档矩阵中提取本体相关关系,基于语义相似度聚类等方法构建本体的设想。采用聚类方法聚集相似对象来生成类目的方法作为辅助来支持本体的构建。郑丽萍规范。(1)等级关系构建模块:等级关系构建模块主要是采用基于层次聚类的等级关系识别算法对筛选出的领域概念进行聚类形成等级体系。
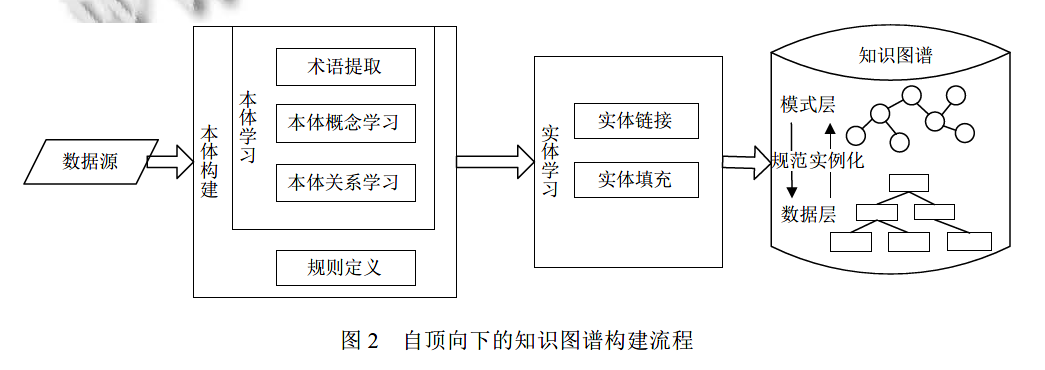
(4)领域关系构建模块:领域关系筛选模块的主要功能是对领域概念的非等级关系,即领域关系进行识别和处理。对语料进行句法处理,抽取其中的主、谓、宾模式作为领域关系的参考。(D)本体形式化模块:本体形式化模块的作用是对识别出等级关系和领域关系的数据进行批处理半自动生成文件,减少手工处理,提高本体的生成效率。6-,Q:B,R5’--8采用相关规则算法发现相关关系。尝试采用?4S决策树算法支持领域专家半自动构建本体。2-9.,建议通过无监督某一特定领域聚类方法来提高本体的构建。开发的系统集成了语法分析工具5TU7V和概念聚类工具!5"I6,可以半自动地进行词义消歧和概念聚类。总体设计本研究中采用了以机器学习和自然语言处理技领域概念的获取领域概念是在特定领域内具有语义的词或短语的集合,是领域知识在文本中的外在表现。领域概念的获取就是从领域文本集合中抽取最能够代表该领域的概念集合,这个过程包括从领域文本中抽取术语集合、词性规范(同义词处理)以及领域概念的筛选和确定。领域概念获取流程图(!)领域候选概念的获取(见图"):在本研究中为了获取领域核心概念,采用了两种方法,一是从领域专业辞典以及汉语主题词表中抽取领域核心词汇,这部分词汇权威、规范、核心,但是数量比较少。
二是采用文本表达法从语料库中抽取其中的重要概念,经过领域概念筛选算法计算主题度*+,确定核心概念集合。(")同义词获取:对于同义词抽取,采用基于模式匹配的方法从专业词典中获取。根据文献[!)],结合语料文本的特点,定义了如下抽取模式:〈释义词〉简称谓之〈同义词列表〉等级关系构建文献[!-]介绍的词类划分标准认为,同一类词必能进入一些同样的上下文环境。因此,如果两个概念在语料集合中所处的语言环境总是非常相似,我们就可以认为这两个概念彼此非常相似,从而认 定这两个词是属于同一类的。 我们的做法是对领域语料文本进行主题特征抽 取,利用相关度统计方法计算每个概念出现的相同 上下文环境,继而通过一定的聚类算法来将上下文 ())找出最近向量距离,形成新的聚类。 新计算类中心,将新的聚类的两个向量 合并。 (3)判断向量的维数,如果大于 ",则转到(")重 新进行下一轮的计算,否则转到(4)。 (4)该层层次聚类结束。 (5)计算某层耦合$内聚比,计算类数目的分布 密度,如果大于阈值,该层合并;如果小于阈值,转到 下一层计算。 (6)判断是否到达底层,如果否,则转到(5);否 层次聚类算法的改造(!)聚类的粒度:层次聚类算法有一个明显的不 足就是每次聚类的结果都是一个二元关系(’ 809’&:$ ;&22 1;2&),这样就导致生成的类簇过细,不宜人阅 读和理解 ,而且不符合本体生成的等级要求。

需要把层次聚类结果进行合并处理,把聚得的类的粒 度变大,每个类下有一定数量的子类。在本研究中 然采用高内聚,低耦合作为聚类结果好的评判标准。 如果某个类的内聚度过低,耦合度过高,就将这个类 合并,以减少聚类的类目数,增加每个类下的类元素 个数。 环境相似的概念聚类,形成概念的等级体系。 设有 },定义几个参数:!)类间耦合度(@>A0A9) 中所包含元素之间的平均相似 小,说明该类的内聚度越高,耦合度越低,也就是该类别的质量越高。 (,)类的数目:为了防止某个类的类元素过多或 者类元素过少,也需要对类元素的数目进行一定的 约束。 分布是可靠性分析中的一个重要分布,本研究采用 领域关系构建基于自然语言处理的识别方法, 主要是利用汉 语的语法知识从汉语语料中抽取主、谓、宾模式构成 三元组为领域关系的构建提供有力的参 识别方法首先利用标注软件对领域文本语料进行词性标注,根据句法规则抽取其中可能的主谓宾三元 组模式,利用筛选算法进行错误剔除,同时对主语和 宾语进行语义类别标注。 (+)句式提取:首先利用词性标注软件,对语料 进行词性标注和浅层句法分析。在汉语中动词是语 言中最重要的词汇和句法分类,在句子中占据核心 地位,并且起到句子主要组织者的作用,提供了句子 的关系和语义框架。
根据汉语的句法规则,手工建 立了 25 种句式抽取规则,利用正则表达式从标注文 本中抽取句子成分。 )动词用法归纳:对于我们来说主要是提取主谓宾形式的语料,因此主要是处理带体词性宾语的 动词。对带体词性宾语的动词后接词语进行统计归 类,总结其所属的语义类。同时,利用《知网》对体词 性动词的前后成分进行聚类和归纳。 词的筛选:本文提出用动词领域特征值 (67 7$89:;$)来衡量动词在该领域中的表达能力,即一个动词的领域特征值越大,则该动词在 领域中的表达能力越强。67 与两个因素有关:动词 的频次和与该动词一同出现的语义实体(名词)的权 值。如果一个动词出现的频次越高,那么它的重要 性可能越高;同时与该动词一起出现的语义实体如 基于自然语言处理的领域关系抽取流程图果都是领域关键词,那么则说明该动词是该领域表 达能力强的动词。 (#"7&C59) %)53#"8A3C8南京:南京理工大学,KHHNO M#4)3"R.C&73237;&65[8 DE]?[KHHNRFKRKP 语言学知识的计算机辅助发现[1]?北京:科 学出版社,FQQN C89?&’9U PPNNK A3&"? ;#C37 T3&*)*7A, ;&65 983"( >#""&75#*[8 DE][? KHHPRHFRHF]? A55C:U 37!4?9C4? J&"&*)53#" ;&65.&(4&"58: #""&75#*8 %27A3&"UC9+%37)53#"U 5#38LHWK (责任编辑王建平) “新信息环境下的知识链接与知识服务”研讨会征文通知知识关联、知识链接与知识服务是信息服务领域比较关注的一个新课题。
为了探讨新信息环境下知识 接与知识服务的理论体系与技术实现方法,研究基于知识链接的知识服务模式,分析基于引文的知识链接服务 中的关键问题和解决途径,促进该领域研究和实践的深入,推动知识服务进程,经研究决定于 KHHQ 息环境下的知识链接与知识服务”研讨会。现通知如下:一、会议征文主题 知识链接服务模式 国内外知识链接及知识服务的具体实践、认识、经验教训 知识组织的理论与实践 叙词表、本体等知识组织工具在知识链接中的作用 基于用户体验的知识构建FH 信息界面的知识组织以及未 列出的其他相关主题。 研究问题明确、具体,立论扎实、论据充分、数据准确;投稿文章必须为以前未在公开刊物或会议上公开发表过的文章,字数在 GHHH 字以上;论文包括中英文标题、中英文摘要(KHH 字以内)、中英文关键词(G 个)、正文、参考文献、作者简介(包括姓名、性别、工作单位、研究方向、电话、


")


")
")
