持续进步的朋友都关注了“1024译站”
这是1024译站的第100篇文章
Web项目多语言(i18n,即国际化)是比较常见的需求,常规的做法大约有以下几种:
每种语言单独开发页面,适用于CMS之类的网站
多语言文本和页面结构分离,运行时动态替换。适用于单页应用(SPA)
直接用网页翻译插件,机器翻译。这些疗效不太理想,同时有一些局限性(前面会提到)
问题
每一种方案都有各自的优点和局限性,具体项目应当按照实际情况选择。近来在工作中遇到的需求是要在现有的项目基础上快速推出多语言版本。
项目是基于Vue.js开发的,早已迭代过好多版本了。虽然一开始是有规划多语言的,也引进了vue-i18n插件。这个插件就是前面第二种方案,用JSON文件管理多语言的文本资源,在Vue组件模板里通过键值引用文本。
并且要管理这种英语键值比较麻烦,命名就很难受。并且阅读代码的时侯也很难从键值快速辨识出对应的英文。前面发觉VSCode有相关的插件,可以显示出对应的英文,并且代码找上去还是有点麻烦。再加上产品的多语言版本仍然没有提上日程,时间久了就嫌麻烦,渐渐地就直接在模板里写英文了。
结果,该来的还是来了。产品忽然说近来要快速推出中文版,后续还有其他语言。一开始的看法是直接用Chrome浏览器自带的Google翻译功能,如何快怎样来。但经过一番测试,发觉了不少问题。
首先机翻的疗效肯定是要打折扣的,但这还在接受范围内。最关键的是会影响到功能使用。哪些问题呢?因为项目是用Vue.js开发的单页应用,页面内容完全是用JS动态渲染的。有些对话框内的文字Google翻译就忽视了。
另外,Google翻译只处理了DOM文本节点,input输入框内的文字(包括placeholder)被忽视了。最严重的问题是,经过Google翻译处理后的DOM元素,居然丧失了Vue响应式特点,数据变化后DOM内的文字不会更新了!
假如要继续采用浏览器Google翻译的方案,就要解决这几个问题。通过调试发觉Google翻译用的JS脚本是嵌入到浏览器VM里的,通过HTTP调用翻译服务,之后更改DOM元素。JS脚本是压缩混淆过的,低格后也很难看。想要找到更新DOM的代码,之后用自己的逻辑去覆盖?耳朵都看瞎了,还是算了。
Google翻译JS代码
鉴于以上缘由,浏览器自带的Google翻译方案基本不考虑了。
现今只剩下第二种方案了,语言配置文件和页面结构分离。上面提过,vue-i18n用得不彻底,假如把所有组件重新规范化,工作量太大了。有没有办法不更改现有代码,也能实现文本翻译呢?很自然地就想到了Google翻译的思路,直接对页面渲染结果进行翻译。自己翻译的优势就是,可以精细地控制DOM操作,例如可以把输入框里的文本和placeholder也翻译下来。
同时,经过研究发觉,Vue组件通过数据绑定渲染下来的DOM元素,包含的文本内容不能直接通过innerHTML或则innerText更改,这样会造成响应式失效。解决办法是操作它的子元素,也就是文本节点(nodeType为3的节点),更改它的textContent属性。
多语言配置映射表
跟Google翻译不同之处在于,我们采用静态翻译,也就是通过多语言配置文件映射。vue-i18n是每种语言打算一个JSON文件,属性名用英语,用命名空间(多层级对象)的形式防止命名冲突。我直接简化了,用一个JS对象储存所有语言版本,键值就是页面用到的英文。随着日积月累的开发迭代,这种英文洒落在几百个文件里……我的做法是用VSCode全局正则搜索,把查找结果复制下来,写一个JS方式把那些字符串处理成JS对象。
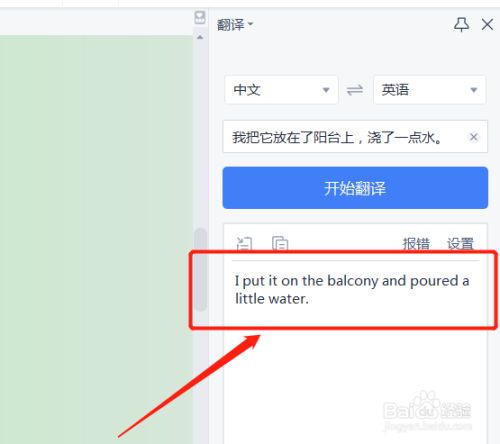
搜索英文
匹配英文的正则(不够全面,有些还参杂了其他符号):
[A-Z]*[\u4e00-\u9fa5][,,!! 0-9a-zA-Z\u4e00-\u9fa5]*
将结果复制到翻译工具翻译,再写一个函数把这种文本合并成对象,并保存到labels.js文件中备用。
var kv = dist.reduce((acc,cur, index) => {
acc[cur]=en[index] || cur;return acc;
},{})
对象的结构大致如下:
// labels.js
export default {
客户性名: {
en: 'Customer Name',
},
// 动态文本,后面会讲到
'剩余{0}台矿机未登记': {
en: '{0} unregistered',
},
xxxx: {
en: 'XXX',
}
}

操作DOM
跟Google翻译类似,我们也采取事后更新DOM的方法来进行翻译。因为是单页应用,随着用户的操作,会不停地更新DOM。一开始的看法是窃听整个body的变化,在反弹里再更新DOM。窃听DOM变化有一个原生的API可用,就是MutationObserver。
mounted() {
this.observeDOM(document.body);
},
methods: {
observeDOM(el) {
let mutationTimer;
const vm = this;
const observer = new MutationObserver(() => {
// 类似于 debounce 的效果,多次调用合并为一次
clearTimeout(mutationTimer);
mutationTimer = setTimeout(() => {
if (!vm.mutationFromTrans) {
translate();
vm.mutationFromTrans = true;
setTimeout(() => {
vm.mutationFromTrans = false;
}, 300);
}
}, 100);
});
const options = {
childList: true, // 监视node直接子节点的变动
subtree: true, // 监视node所有后代的变动
attributes: true, // 监视node属性的变动
characterData: true, // 监视指定目标节点或子节点树中节点所包含的字符数据的变化。
};
if (this.language === 'en') {
observer.observe(el, options);
}
},
},
然而试过以后发觉这会造成无线循环,由于没有判定DOM的变化来自用户操作还是翻译本身。所以代码里前面加了判定,并且结果仍然不理想。这些操作代价太大了,页面性能受了很大影响。并且还有个很显著的问题,就是步入到新的界面会闪一下,从英文弄成中文。这个体验太糟糕了。旁边有改进办法。
翻译
先来来看下翻译的过程。翻译就是从多语言配置对象里查找匹配的属性名,获取对应语言的属性值。这对于静态文本来说比较简单,直接用属性名就好了。并且对于动态的文本如何处理呢?因为中英文抒发形式不一样,这些文本不能简单地拆分成多个部份单独处理,而是要在英语的抒发方式里替换动态数据。
我的做法是使用带格式的键值,例如{0}这样的占位符。在查找的时侯,优先匹配固定文本。由于大部份情况是固定文本,但是这些匹配是O(1)时间复杂度的,优先判定会增强性能。匹配失败的时侯才去提早构造好的正则列表里遍历匹配,成功则提取正则匹配的group用于替换动态数据。假如失败,说明没有对应的翻译,直接返回原始字符串就行了。
const keys = Object.keys(words);
// 提前缓存正则,避免重复执行消耗性能
const regExps = keys.reduce((acc, key) => {
// 模板型键名
if (key.indexOf('{0}') > -1) {
const reg = new RegExp(key.replace('{0}', '(.+)'));
acc.push({
expression: reg,
key,
});
}
return acc;
}, []);
export function translate(el = document.body, lang = 'en') {
const kv = words;
if (!el.querySelectorAll) {
return;
}
const _trans = label => {
const text = label?.trim?.();
if (!text) {
return label;
}
if (kv[text]?.[lang]) {
return kv[text]?.[lang];
}
for (let index = 0; index < regExps.length; index++) {
const regItem = regExps[index];
const m = text.match(regItem.expression);
if (m) {
return kv[regItem.key][lang].replace('{0}', m[1]);
}
}
return text;
};
[...el.querySelectorAll('*')].forEach(node => {
// 不能直接修改node.innerText,会导致Vue响应式失效
// node.innerText = kv[node.innerText?.trim?.()] || node.innerText;
if (node.nodeName === 'INPUT' && node.type === 'text') {
node.value = _trans(node.value);
node.placeholder = _trans(node.placeholder);
}
const textNodes = [...node.childNodes].filter(n => n.nodeType === 3);
textNodes.forEach(textNode => {
textNode.textContent = _trans(textNode.textContent);
});
});
}
改进后的DOM操作
后面提过,假如在DOM渲染后再执行翻译,页面性能十分差。于是想到了Vue本身的渲染过程,能不能拦截Vue组件渲染过程,插入一些额外的逻辑呢?通过扒源码发觉,Vue原型上有个__patch__方式,每次更新DOM的时侯就会执行。就从这儿入手,重画这个方式,对还没挂载到文档树的DOM元素执行翻译操作。
const __patch__ = Vue.prototype.__patch__;
Vue.prototype.__patch__ = function() {
const elm = __patch__.apply(this, arguments);
if (this.$store?.getters?.language) {
translate(elm, this.$store?.getters?.language);
}
return elm;
};
至此,基本完成了多语言翻译。经过权衡对比,这个方案算是比较省时省力又能完成需求的了。其实,这些方案或多或少对页面性能有一定影响,虽然降低了DOM更新的时间。尤其是动态文本较多的情况,涉及到遍历正则匹配,比较历时。假如你们有更好的方案,欢迎留言!
类似的思路,之前也用到过。参考这篇,也是一种歪门邪道,当心走火入魔哦。
顺手点“在看”,每晚早上班;转发加关注,共奔小康路~
本文分享自陌陌公众号-1024译站(trans1024)。





")

