第 29 届 SOSP 于 2023 年 10 月 23 日 - 10 月 26 日在德国的科布伦茨小镇召开。本次会议共收到 232 篇投稿,共接收 43 篇论文,录取率为 18.5%。
SJTU-IPADS 小分队现场合照
本次大会共选出3篇最佳论文,分别是:
TreeSLS: A Whole-system Persistent Microkernel with Tree-structured State Checkpoint on NVM
Fangnuo Wu (Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University), Mingkai Dong (Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University), Gequan Mo (Shanghai Jiao Tong University), Haibo Chen (Shanghai Jiao Tong University)
Validating JIT Compilers via Compilation Space Exploration
Cong Li (Nanjing University), Yanyan Jiang (Nanjing University), Chang Xu (Nanjing University), Zhendong Su (ETH Zurich)
Enabling High-Performance and Secure Userspace NVM File Systems with the Trio Architecture
Diyu Zhou (EPFL), Vojtech Aschenbrenner (EPFL), Tao Lyu (EPFL), Jian Zhang (Rutgers University), Sudarsun Kannan (Rutgers University), Sanidhya Kashyap (EPFL)
热烈祝贺获奖的各位老师和同学们!
接下来的几天,IPADS 的同学们将按照会议日程对论文内容进行分期评述,本期是 Day 1 论文的评述。会议现场的Q&A我们也会后续更新在知乎账号(可点击“阅读原文”访问)。
Session 1: Kernel Design and Testing
TreeSLS: A Whole-system Persistent Microkernel with Tree-structured State Checkpoint on NVM
Fangnuo Wu (Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University), Mingkai Dong (Institute of Parallel and Distributed Systems, Shanghai Jiao Tong University), Gequan Mo (Shanghai Jiao Tong University), Haibo Chen (Shanghai Jiao Tong University)
Single-level Store:解放应用进行数据持久化工作
数据持久化是应用为用户提供服务所需要考虑的核心问题。然而,在当前主流操作系统上实现数据持久化面临一个底层的根本矛盾:长久以来,操作系统可用的数据存储设备都不能同时具备读写性能和数据持久性。主流的操作系统一直都构建在DRAM和disk两种设备上。disk具备数据持久性,但是它的读取效率很低,且不具备可以让CPU直接读写其中数据的字节访问接口;DRAM虽然有良好的读取效率和字节访问接口,但存放在其上的数据并不具有持久性。为了在上述的设备限制下同时取得性能和数据持久性,操作系统不得不同时使用两种设备,将运行时的数据放在DRAM以获得性能,并提供文件系统等接口,将数据从DRAM持久化到disk上以获得数据持久性(如图1所示)。
图1:DRAM/Disk的两层存储结构
这一DRAM/disk的两层存储结构要求运行在系统上的应用主动持久化自己的数据,因此导致应用需要进行大量的代码开发工作,如RocksDB使用了8万行代码实现持久化;同时,大量的代码量导致代码容易出现错误,很多成熟的应用至今都在修复与持久化相关的问题;此外,每个新应用都需要从头进行一遍数据持久化相关的逻辑开发。单层存储(Single-level Store, SLS)打破了主流的DRAM/disk两层存储模型,它通过checkpoint/restore技术将DRAM层向下延伸至包括disk,将永久性和短暂性数据以及系统状态一起进行透明持久化管理。因此,应用程序可以在“单层”存储中执行和存储数据,并且不用负责数据的持久化,而是可以依赖操作系统的透明的数据持久化。
现有SLS的问题
在过去的几十年中,多个工作(Multics,EROS,Aurora等)提出了在传统存储设备上设计和实施SLS的方案。然而,现有的SLS依然存在两个主要的问题:1. 持久化开销大:现有的SLS通过checkpoint技术在DRAM/disk之上提供了一个单层存储的假象,因此会导致写放大等性能开销。2. 不支持透明的外部同步性(external synchrony):现代应用程序依赖于外部可见操作的即时持久化,即外部同步性,来向客户端等外部实体提供服务。现有的SLS系统为应用程序提供了自定义API以确保外部同步。然而,修改应用程序以适应这些API以实现正确的数据持久化需要非常重要的工作,这与SLS系统的目标相矛盾。
本工作insights
为了解决上述的问题,提供一个低开销、具有透明的外部同步性的SLS系统,本工作提出了两个核心的insights。
1. 使用NVM设备构建SLS系统
NVM结合了disk的持久性和DRAM的可字节寻址以及读写性能,是一种天然的单层存储设备。然而将系统的DRAM/disk结构替换为NVM并不能直接获得全系统持久性。这是由于系统中仍然存在断电后会丢失的数据,即使如今的eADR技术可以将cache也持久化,CPU寄存器,设备寄存器等状态依然会丢失。因此依然需要一种checkpoint技术来持久化这些易失的数据,并维护NVM上数据与被checkpoint的易失数据之间的一致性。
2. 基于microkernel构建SLS系统
考虑到我们需要checkpoint系统状态,如何高效、简洁地获取系统状态也是我们的目标之一。Microkernel有两大优势:一方面,Microkernel只在内核实现最基础的功能,系统服务都实现在用户态,原先系统服务的状态对象也完全维护在用户态page中,因此checkpoint时不需要了解这些复杂的系统对象;另一方面,Microkernel通常基于capability机制进行权限管理,如图2所示,每个进程有一个capability group,会引用所有该进程有权限访问的状态对象,而系统中所有的对象通过这一方式可以组成一棵capability tree,持久化这一就相当于持久化整个系统。
图2:capability tree结构
设计:TreeSLS
TreeSLS通过Microkernel高效地抽象出了系统状态,通过将capability tree放在NVM设备上,并设计了一个高效的、针对NVM的checkpoint manager来定期暂停整个系统并持久化所有状态。
图3:TreeSLS架构
TreeSLS通过对象版本管理、混合page持久化实现了低开销的持久化方案。此外,TreeSLS通过在网络服务中延迟回复实现了透明的外部一致性。
效果
1. TreeSLS可以在100μs左右完成全系统的持久化
2. 在 1ms 一次的高频检查点创建下,相比真实应用程序的原生持久化支持(e.g. WAL)可以取得至多2.5倍的性能提升
Memtis: Efficient Memory Tiering with Dynamic Page Classification and Page Size Determination
Taehyung Lee (Sungkyunkwan University), Sumit Kumar Monga (Virginia Tech), Changwoo Min (Igalia), Young Ik Eom (Sungkyunkwan University)
背景
由数据中心工作负载推动的不断增长的内存需求是新的内存技术创新(如NVM、CXL)背后的驱动力。分层内存是一种很有前途的解决方案,它利用具有不同容量、延迟和成本特征的多种内存类型,在满足内存需求的同时降低服务器硬件成本。
现有内存分层系统的问题
之前关于内存分层的工作往往无法做出最优的页放置决策,因为它们依赖于各种启发式方法和静态阈值,而没有考虑整体的内存访问分布。此外,为应用程序确定合适的页大小也很困难,由于内存访问并不总是均匀的,使用大页不一定能得到正向收益。
如下图所示,此前的分层内存系统利用 page fault,PT scanning,hardware-based sampling等方法进行访存追踪。然而基于page fault的系统会显著增加内存访问的 latency,基于PT scanning的系统的可扩展性较差,基于硬件sampling 的工作无法追踪 subpage access。
设计
本文提出Memtis,一种利用informed decision-making机制来制定页大小和页放置策略的分层内存系统。Memtis利用已分配页的访问分布,以最优的方式逼近热数据集的fast tier capacity。
如下图所示,Memtis 主要解决三个问题:(1)如何使用基于硬件的内存访问采样,以细粒度和轻量级的方式跟踪内存访问;(2)如何根据整体内存访问频率分布,动态准确地确定热页和冷页;(3)如何动态确定页大小(大页与普通页),以在不浪费fast tier 内存的情况下降低转换成本。具体来说:
(1)Memtis使用Processor Event-Based Sampling (PEBS) 对内存访问进行采样。由于PEBS样本包含精确的内存地址,使得Memtis可以支持细粒度的访问跟踪。在Memtis维护一个内核后台线程(ksampled)来处理采样的地址,Memtis可以动态调整访存采样频率,确保CPU开销在阈值(< 3%)以下。
(2)Memtis使用page access counts来维护所有已分配页面的热度分布(下图中的page access histogram),并且利用该数据做出最佳的memory tiering决策,将最热的页放置在fast tier以最小化访问延迟。
(3)Memtis在Linux中默认使用Transparent Huge Pages(THP)来减少地址翻译的开销。然而,单一页大小并不适用于所有工作负载。例如,如果一个大页中只有一小部分子页被频繁访问(即,大页的利用率很低时),那么应该只将热点子页迁移到fast tier。Memtis通过split benefit estimation来检测这种情况。Memtis使用ksampled维护的emulated base page histogram来估计仅使用普通页时的最大命中率,并将估计的最大命中率与从PEBS的采样记录中获得的实际命中率进行比较,以此来估计拆分大页的潜在收益(下图中绿色的部分),如果潜在的好处很大,Memtis会选择子页面中访存模式最不均匀的大页作为拆分候选页。然后,在后台对大页进行拆分,并根据大页中维护的子页访问信息将每个分片后的子页放置到相应的内存层。
测试
下图展示了使用NVM作为容量层时分层内存系统的性能比较。Memtis几乎在所有情况下(23/24)都表现最佳,特别是在geomeanbenchmark 下的性能比次优系统高出33.6%。实验结果表明,Memtis在各种内存设置和访问模式下均表现良好。
Snowcat: Efficient Kernel Concurrency Testing using a Learned Coverage Predictor
Sishuai Gong (Purdue University), Dinglan Peng (Purdue University), Deniz Altınbüken (Google DeepMind), Pedro Fonseca (Purdue University), Petros Maniatis (Google DeepMind)
背景
内核并发漏洞模糊测试(fuzzing)通过随机生成测试用例检测漏洞。由于并发测试用例的输入空间大(多条执行序列、多种调度方式),想要高效地生成有价值的测试用例并不容易。
为了加快漏洞的发现,可以在真正执行一个测试用例前,先用机器学习模型预测该用例是否有价值(例如能够提高代码覆盖率),只执行有价值的测试用例,如下图所示。
然而,在内核并发测试场景下,现有的机器学习方案存在不足。
(1)一种方案将测试用例代码作为模型输入,由于内核接口简单但内部结构复杂,测试用例代码所含的信息量不高,该方案预测准确性不足。
(2)另一种方案将完整的内核执行流输入模型,由于内核执行流复杂,该方案的预测开销大,甚至可能高于实际执行测试用例的开销。
本文提出一种新的测试用例有效性预测模型,可以兼顾预测的准确性与性能。
观察
如果一个单线程测试用例,串行运行时无法覆盖到某个代码块,但在与其他测试用例并发运行时可以覆盖到这个代码块,那么这个测试用例较有可能发现并发漏洞。
模型设计
模型输入:模型的输入是一个并发测试用例,包含两个单线程测试用例和交替执行时的调度方案。
模型输出:模型的输出为二进制向量,表示执行并发测试用例时实际会覆盖到的代码块。测试框架可以依据以下策略决定是否执行测试用例。
模型由两部分组成,第一部分为Transformer,负责将控制流图中的代码块转化为向量表示,第二部分为GNN,负责根据输入的控制流图生成二进制向量。
测试
模糊测试效率:下图中PCT为传统模糊测试(SKI),MLPCT添加了机器学习预测,横轴为测试耗时,纵轴为发现的Data Race个数(包含良性的Data Race)。S1/S2/S3为不同的执行策略。
相比于PCT,MLPCT可以更快发现Data Race(下图a)。旧版本内核训练的模型经过fine tune后即可在新版本使用,降低了训练开销(下图b)
发现漏洞:在Linux 6.1内核上发现了17个新的并发漏洞,其中13个得到确认,6个得到修复。
One Simple API Can Cause Hundreds of Bugs An Analysis of Refcounting Bugs in All Modern Linux Kernels
Liang He (Institute of Software, CAS China), Purui Su (Institute of Software, CAS China), Chao Zhang (Tsinghua University), Yan Cai (Institute of Software, Chinese Academy of Sciences), Jinxin Ma (CNITSEC)
引用计数(refcounting)在Linux内核中被广泛使用。然而,它需要对相关API进行手动调用。在实际应用中,对这些API的缺失或不正确的调用引入了许多错误,这些错误被称为引用计数错误。为了评估这些错误在过去和未来的严重性,本文对它们进行了全面的研究。
具体而言,本文研究了Linux内核中的1,033个引用计数错误,并研究了这些错误的特征,发现大多数的错误最终会导致严重的安全问题。此外,本文分析了实现和开发人员方面的根本原因(即人为因素),结果显示引用计数API的粗心用法通常会引入数百个错误。最后,文章提出一组anti-pattern来总结和揭示引用计数错误。在最新的内核发布版本中,作者总共发现了351个新的错误,其中240个已经得到确认。
引用计数错误
引用计数错误广泛存在于内核中,作者统计了从2005年到2022年的Linux内核信息,发现总共有1033个引用计数错误存在于753个不同版本的内核中。
文章主要关注两类引用计数错误,Missing-Refcounting Bugs 和 Misplacing-Refcounting Bugs,前者是开发者忘记增加/减少引用计数,后者是没有将引用计数的增减指令放在正确的位置。
调查结果
安全问题:
71.7% (741/1033)的bug会导致内存泄漏的问题,超过一半 (57.1%)可以通过减少同一函数中不匹配的引用计数操作找到。
28.3% (292/1033)的bug会导致use-after-free (UAF)问题,9.1% (94/1033)的bug可以通过检测是否在减少引用计数后对引用内容进行访问找到。
Bug 分布:
引用计数错误在Linux内核中满足长尾分布,82.4%的bug在“drivers”、“net”和“fs”子系统中,有56.9%的bug在“driver”中。
Bug 生命周期
超过75.7%的bug需要超过一年的时间才能被修复,甚至有19个bug在内核中存在了超过10年时间。
有23个bug从Linux kernel v2.6.y存在到v5.x和v6.x,这意味着网络上大部分机器都会受到这些bug的影响。
根本原因
作者发现如果引用计数 API 实现中存在微小偏差,即一些与大多数实现不同的额外行为或操作,它可能引入数百个错误。
具体而言,对于导致内存泄漏的引用计数错误,有两个潜在的根本原因。首先,当开发人员对标准的引用计数算法引入任何微小的偏差时,会导致许多错误。例如,作者发现一个特殊的API,pm_runtime_get_sync(),导致了94个错误。主要原因是,即使在遇到错误并返回错误代码时,此API也会增加引用计数器(以下简称refcounter),在这种情况下,调用者通常会忽略减少操作,从而导致内存泄漏。其次,当开发人员为了代码简洁性将增加refcounter的操作添加到某些宏或类似的API中时,即使有经验的内核开发人员也经常会忽略减少操作,最终导致引用计数错误。这个问题也引发了大量的错误。
对于导致UAF(使用后释放)错误的错误,作者也发现了两个关键原因。首先,当开发人员在调用减少引用计数的API后访问对象,本文中称之为使用后减少(UAD)问题,可能会导致潜在的UAF错误。其次,由于逃逸分析鼓励引用计数的省略,内核开发人员选择手动完成优化以提升性能。不幸的是,他们经常错误地在创建新引用时省略了增加引用计数器的操作,这可能导致过早释放。上述两个问题中的每一个都引起了许多引用计数错误。
解决方案
基于上述根本原因,作者提出了9种由语义模板描述的anti-pattern。并且为每种anti-pattern设计和实现了一个静态检查器。这个检查器在最近几个内核版本中共检测到了351个新的错误,而在撰写本文时,已经确认了其中240个。通过深入分析这些新错误,作者发现它们的特征与历史错误非常相似。基于这一事实,作者认为如果开发人员或研究人员开始更多地关注这篇研究的特征和经验教训,引用计数错误可以大大减少。
Session 2: Reliability
Validating JIT Compilers via Compilation Space Exploration
Cong Li (Nanjing University), Yanyan Jiang (Nanjing University), Chang Xu (Nanjing University), Zhendong Su (ETH Zurich)
Problem
即时编译(Just-In-Time compilation)是一种在程序运行时动态地进行编译的技术,该技术广泛应用于语言虚拟机(LVM)领域,程序中经过即时编译的部分代码将从字节码解释执行模式变为本地代码执行。同时,现代语言虚拟机中的即时编译器(JIT Compiler)通常实现了一系列非常复杂的编译优化,使得即时编译成为提升程序运行性能的有效方法。然而,即时编译器实现上的复杂性也使得它成为现代语言虚拟机中主要的错误来源,相关的正确性测试和检验工作成为了学术和工业界关注的焦点。由于即时编译往往基于对给定程序执行热点的测量,动态制定编译决策,合成的测试程序可能不能触发即时编译,或只能触发少量即时编译路径。如何对即时编译器的不同编译决策进行充分测试已经成为影响其测试有效性的严峻问题。
Insight
为解决这一问题,本文首先提出编译空间(Compilation space)概念,同一程序在给定LVM上所有可能的编译产物被形式化地定义为该程序的编译空间。如下图所示:对于包含4个类方法的程序,假设即时编译器以方法为单位决定是否进行编译,那么该即时编译器有可能产生16种不同的编译决策,从而产生包含16种不同的编译产物的编译空间。
本文指出,验证JIT Compiler正确性的有效方法在于进行编译空间搜索(Compilation space exploration),通过产生并执行给定程序编译空间中不同的编译产物、检查结果是否与解释执行的结果一致,便能够充分验证即时编译器不同编译决策的正确性。然而,即时编译器通常不会暴露足够的接口来控制其编译决策,如何不侵入式地修改LVM是实现编译空间搜索的一个重要的挑战。
Design
为解决这一挑战,本文进一步提出了JoNM(JIT-relevant operations Neutral Mutation)策略,该策略的核心观察在于:即时编译器通常通过测量代码中部分JIT相关操作,如函数调用次数、循环体执行次数等指标,决定代码的冷热程度。通过在源码层面调整JIT相关操作的执行次数,便可以影响即时编译器的编译决策。同时,JoNM要求修改不影响程序的语义(如插入空循环)。因此,如果执行不同的修改版本结果不一致,则说明不同的JIT编译决策改变了程序执行结果,从而揭示了JIT编译器中的漏洞。基于JoNM策略,本文针对JVM实现了Artemis系统,Artemis能够自动在Java代码中插入对程序执行结果中性的循环,从而使得JIT Compiler认为被修改的位置存在热点代码,因而执行方法编译或栈上替换(On-Stack Replacement)。Artemis使用JavaFuzzer工具产生种子程序(seed),对于给定的种子程序,Artemis随机选择程序代码位点,插入以下三种模式的循环结构:
1. Loop Inserter(LI.loop_skeleton):该结构中不包含任何种子程序中原有的代码,而是插入一个合成的循环体。循环体stmts可能为空或来自于JVM测试套件,循环次数则被设定为一个足以触发OSR编译的值,从而引发JIT编译。由于合成的循环体stmts可能使用原有代码中的变量,Artemis会备份所有被使用的变量的值,在合成的循环执行完毕后恢复,从而保证不影响程序原有语义。
2. Statement Wrapper(SW.loop_skeleton):该结构将选取的代码位点处原有的语句placeholder:stmt移动到在合成的循环中,从而使得包含原始语句在内的循环体被OSR编译。Artemis通过exec标志位保证原有语句只被执行一次。
3. Method Invocator(MI.loop_skeleton):该结构在代码中原有的函数placeholder:method调用前插入一个循环,循环体中将多次调用该函数从而触发JIT方法编译。Artemis通过修改原有的函数代码,在函数体开头添加控制语句if ( P. m_ctrl ) { ; return ; },并在调用合成的循环体调用该方法前设置P.m_ctrl = true,确保在合成的循环中仅增加方法的执行次数,但不执行原有的函数体。
上述循环结构的插入使得修改后的程序在运行过程中JIT编译器的编译决策产生显著差异。Artemis会自动运行修改后的程序,并与种子程序运行结果进行对比,若两者结果不同则报告JIT编译器漏洞。
Evaluation
如下表所示,Artemis在HotSpot、OpenJ9和ART这三个JVM上共发现85个即时编译器漏洞,其中53个已被确认或修复。这些漏洞中12个OpenJ9漏洞被标记为blocker级漏洞,10个HotSpot漏洞被标记为P3级以上漏洞(严重功能受损)。
在性能测试方面,作者在使用Ryzen Threadripper 3990X处理器的服务器上使用16个核心进行测试,结果显示:对于每个JavaFuzzer生成的程序,Artemis平均花费1.65s对源码进行分析,随后随机生成8种修改的版本,每个版本的合成平均花费157ms,并使用约15s的时间完成原始程序及所有变种的执行,说明Artemis系统具有良好的实用性能。
Automated Verification of an In-Production DNS Authoritative Engine
Naiqian Zheng (Peking University) Mengqi Liu (Alibaba Cloud) Yuxing Xiang (Peking University) Linjian Song (Alibaba Cloud) Dong Li (Alibaba Cloud) Feng Han (Alibaba Cloud) Nan Wang (Alibaba Cloud) Yong Ma (Alibaba Cloud) Zhuo Liang (Alibaba Cloud) Dennis Cai (Alibaba Cloud) Ennan Zhai (Alibaba Cloud) Xuanzhe Liu (Peking University) Xin Jin (Peking University)
本文为阿里的工业的DNS权威服务器提供了形式化验证的框架。对于复杂系统的形式化验证一般采用分层的方法(Layered Verification),但是工业级的DNS权威引擎本身缺少模块化的设计,并没有干净的接口和数据结构封装。因此,本文基于分层验证,提出了一种摘要方法(summarization approach),通过运行全路径符号执行(full-path symbolic execution)来累计所有路径条件和计算效果,然后以抽象形式将模块的行为表示为一组输入-效果对(input-effect pair)。此外,为了适应DNS权威引擎未来可能的迭代版本,本文确定了跨不同版本保持稳定的常见依赖库模块,并精心设计了它们的抽象,使其适合自动推理。本框架在不到一周人(one person-week)的投入下,成功地识别和防止了DNS权威引擎不同版本中数十个关键错误进入生产环境
背景
DNS将人类可读的域名转换为机器可读的IP地址。作为DNS的核心,DNS权威引擎将传入的查询与本地的DNS权威记录进行匹配,并组合成DNS响应。阿里的DNS服务器每天服务了O(10^12)的DNS请求。然而,要正确实现DNS权威引擎并不容易,因为DNS权威协议非常复杂。许多不同类型的DNS权威记录与它们各自不同的处理逻辑相互交织在一起,导致在DNS权威引擎的实现中存在着复杂的函数逻辑关系。同时,DNS的正确性会影响整个internet的正确工作与否,甚至是网络访问的安全性。
另一方面,源代码的形式化验证用于保证没有错误的存在。为了验证系统的功能正确性,需要定义一个形式化规约(specification),描述该系统的预期行为,然后使用验证器严格检查源代码中的每条可能的执行路径是否符合该规约。
挑战与目标
本文的目标是建立DNS-V,一个验证工业DNS权威引擎的验证框架,在开发时自动验证,同时也可以移植于新的迭代的版本。
挑战是:工业的DNS权威引擎缺少模块化,接口不够干净,并且数据结构缺少干净的封装(可以从模块外部访问)比如下面的例子。
一个分层的验证结构需要给每个层(模块)定义一个抽象规约,并证明调用这个规约等价于调用这个层之下的源码,这样我们可以独立验证每个层。但是显然工业级的DNS引擎不具有分层的设计(之前的类似工作通常从头构建一个系统,而不是直接应用在工业级的系统中),并且由于该工业级引擎本身的一次次更新和加入新的功能,引擎代码和接口变得复杂,不同模块和数据结构变得耦合。同时,很多功能的底层实现也让自动推理变得困难。
目标
1. 形式化验证的安全:DNS权威引擎给定任何输入请求不应该有运行时错误 ;和功能正确性:返回的DNS回复对于任何请求都是正确的,相对于最顶层的规约。
2. 对于迭代的新版本的可移植性:工业DNS引擎会常更新,新的补丁可能会引入新的bug。验证框架应该对新更新的验证需要很少的工作。
设计
DNS-V仍然使用传统的分层结构和符号执行去完成自动化的验证,不同点是,为了解决上文描述的挑战,本文的创新点是提出了“摘要” (summarization)。
本文衍生了传统的分层结构,为缺少well-defined functionality的模块自动计算“摘要规约”(summary specification)。“摘要”会运行全路径的符号执行,并积累所有的路径条件和计算结果(比如写入内存、返回值等),然后将模块的行为描述为一组输入-效果对(input-effect pair)的集合。本文通过“摘要”来保证验证的模块化和高效率,避免人为定义不干净程序的每层规约的困难。
“摘要”通常很困难,因为模块计算的复杂性,然而,本文观察到DNS权威引擎中的解析模块遵循有限的处理模式,这使它们适合自动摘要。此外,DNS-V以一种灵活的方式设计了验证器的内存模型,以适应正在使用的DNS权威引擎中的糟糕的数据结构封装。数据结构可以部分抽象化,抽象规范不再需要区分抽象和具体的数据。
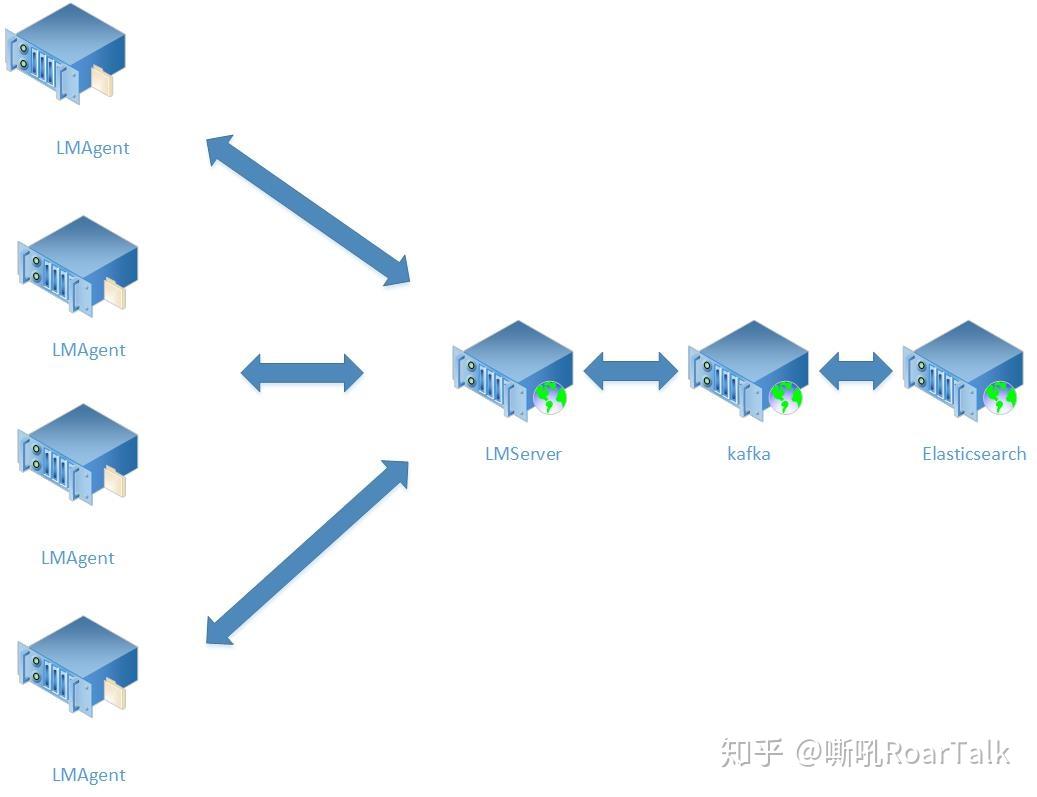
工业的DNS权威引擎包含了2000行GO代码,其中黄色模块表示底层的库(在不同版本更新的权威引擎中保持稳定),蓝色模块执行DNS匹配操作,其中Resolve模块是顶层进入点,满足顶层规约(根据RFC协议手动制定)。我们的目的是验证DNS权威引擎的实现满足顶层规约。
DNS-V的验证工作流包含:首先将GO用GoLLVM翻译成LLVM IR,对于黄色的模块,手动提出抽象规约,使用自动化的验证工具去验证规约确实捕获了源码所有可能的执行行为。对于蓝色的无法直接融入分层验证的模块,使用了创新的基于“摘要”的方法,自动生成“摘要规约”。这些模块通常合适摘要规约,首先这些模块有清晰的输入输出模式,其次,这些模块的分支条件很简单,可以高效的被SMT solver检查。
对于不干净的数据结构,DNS-V设计了灵活的内存模型,支持数据结构的部分抽象。现有的验证技术明确的区分抽象状态和具体的内存状态,像下图:
无法支不完美的数据结构封装(有外部访问),DNS-V让抽象规约不再关注内存状态是具体的还是抽象的。DNS-V将内存建模为一组不重叠的块,由LLVM指针引用。每个块包含一个抽象数组或结构体,其内容可以是具体值或抽象值。这样,DNS-V可以部分抽象化数据结构中的某些字段。虽然抽象化字段只能由规约访问,但其余字段既可以由规约操作,也可以由普通的LLVM指令操作。
下图展示了DNS-V的整个工作流:
对于任何一个层(模块),要么使用refinement-based verification来验证一个手动提供的功能规约,要么是自动的摘要规约,验证器整合所有的路径条件和计算效果,生成一个抽象的摘要规约。
评估
DNS-V被应用于阿里的生产力DNS权威引擎两个月,并验证了四个不同版本的代码。DNS-V找到并避免了O(10)的bug被正式投入生产,包含运行时错误和功能正确性的违背。本文发现每个新版本都会带来新的bug。小于1%的执行路径会导致错误,因此单纯的测试用例集合无法测出。一些错误的例子如下表:
把验证移植到DNS权威引擎的新的版本只需要极少的人力成本,如下表:
移植并验证每个版本的软件花费大约one person-week,对于每一层,DNS-V执行自动摘要和符号执行完成验证的时间小于1分钟:
Acto: Automatic End-to-End Testing for Operation Correctness of Cloud System Management
Jiawei Tyler Gu (University of Illinois Urbana-Champaign), Xudong Sun (University of Illinois Urbana Champaign), Wentao Zhang (University of Illinois Urbana Champaign), Yuxuan Jiang(University of Illinois Urbana Champaign), Chen Wang (IBM Research Yorktown Heights), Mandana Vaziri (IBM Research Yorktown Heights), Owolabi Legunsen (Cornell University Ithaca), Tianyin Xu (University of Illinois Urbana Champaign)
问题
现代云系统越来越多的由操作程序(operator)来管理,如Kubernetes 、Twine 和 ECS等云管理平台的operator基于状态调节来实现声明式接口,只需要声明所需的系统状态,operator会自动将系统从当前状态调节到声明的状态。
由于operator的广泛使用,operator的快速开发和部署的要求使其质量保证成为当务之急。operator的正确性对系统可靠性至关重要。错误百出的operator会损害生产环境中的系统。
作者在研究GitHub 上的 50 个开源 Kubernetes operator项目及测试,总结了几个发现:
因此本文认为目前对于operator的测试设计存在不足,手动编写e2e测试既繁琐又不充分,因此本文希望提出一个自动化的测试工具。
但是对于自动化工具来说,存在两个基本挑战:(1) 在巨大的状态空间中探索相关的系统状态;(2) 从所有不同的起始状态正确协调管理系统。
上述问题的存在,本文提出了Acto,这是首个用于云系统operator端到端测试的自动技术和工具。Acto 可自动生成端到端测试,来测试operator的正确性。
设计
核心设计
Acto 是一种以状态为中心的测试技术。它通过对operator和管理系统执行e2e测试,来进行正确性的测试。为此,Acto 在测试过程中不断生成新操作。并且Acto会检查operator是否总能正确地将系统从当前状态调节到所需状态,一旦发生错误,Acto发出警报。
本文对operator提出了三个正确性要求:
1. operator会将管理系统调节到有效的、可达到的理想状态,无论其当前或之前的状态如何
2. operator可以通过回滚到之前的良好状态,从隐式或显式错误状态恢复管理系统
3. operato应防止错误操作将错误状态带入管理系统
设计细节
Acto 有两种工作模式:黑盒模式(Acto■)和白盒模式(Acto□)。Acto■ 接受两个输入:
1)用于构建和部署目标operator的清单;
2)operator接口提供的状态声明规范(例如,Kubernetes operator的自定义资源定义)。
Acto□ 需要额外的输入:用于静态程序分析的operator源代码,用来进行语义推理和谓词分析。Acto会将Acto 将操作建模为一对操作:
其中 S^c 表示当前系统状态,D 是对有效预期状态的声明。如果操作成功,就会触发一个状态转换:
其中 S^D 满足D,即
如果操作失败,系统就会进入错误状态,即:
Acto 使用以下三种测试策略系统地探索状态空间:
1. Single operation:如图 a 所示Acto 生成一个期望状态 的声明,触发一个操作将当前的系统状态 S^c 与期望的系统状态 S^D 调和,并检查
单次操作适用于初始系统状态 S^c = S_0。
2.Operation sequence:如图b所示,将单一操作扩展为测试活动,测试活动由一系列操作组成。测试活动克服了单一操作策略的限制,即必须始终从初始状态S^c = S_0开始。在测试活动中,先前的操作会将系统带入新的状态,这些状态会成为后续操作的起始状态
3. Error-state recovery:如图c所示,如果系统处于错误状态 S^e,operator负责从 S^e 恢复,将系统从 S^e 调节回先前的健康状态 S_{i-1}。随后的操作从 S_{i-1}开始
Acto 将这三种测试探索策略(图 a-c)结合起来,在一个测试活动中实现状态转换序列,如图 d 所示。
Acto使用oracles检查管理系统调节后的状态是否与指定的期望状态相匹配。如果匹配,Acto 会报告操作成功。否则,Acto 发出警报,用户可以检查警报,以发现错误操作的错误或漏洞。对于不匹配的情况,存在显式和隐式两种。
1. 对于显式不匹配来说,Acto 实现了用于检查显式错误状态(如异常、错误代码和超时)的状态错配的机制。这些机制包括:1)扫描operator的错误日志,查找意外异常,例如 Go 中的 panic 信号;2)检查管理系统的运行时状态;3)检查操作是否返回错误代码或未能按时完成
2. 对于隐式不匹配来说,使用了两种方式来检测隐式状态不匹配
(1)Consistency oracle:Acto 会检查operator和管理平台(如 Kubernetes)视图中的$$S^i \not\models D^i $$。存在漏洞的operator视图可能会显示 $$S^i \models D^i $$ ,而管理视图则显示 $$S^i \not\models D^i $$。这种视图不一致很可能表明存在错误
(2)Differential oracle:这种方式利用了操作符应遵循的水平触发原则:应从不同的起始状态到达相同的期望状态。因此,对于每一对过渡对:
Acto 在根据进行状态调节后,检查 S_i 和 S_i^{'} 是否匹配。
测试
Acto在11家运营商中发现了56个新漏洞,已确认操作系统存在42个bug,其中30个已经修复,如下图所示。
在8台机器的集群上,Acto使得所有operator的测试活动在不到8小时内完成。其中5个operator只需要一台机器也可以在8小时内完成,如下图所示。因此,Acto可以每晚运行来检测operator。
Grove: a Separation-Logic Library for Verifying Distributed Systems
Upamanyu Sharma (MIT CSAIL), Ralf Jung (ETH Zurich), Joseph Tassarotti (New York University), M. Frans Kaashoek (MIT CSAIL), Nickolai Zeldovich (MIT CSAIL)
背景与挑战
分布式系统由于其极高的复杂性和易出错性,使得开发者面临着各种挑战。形式化验证是严格建立此类系统正确性的一种有效方法。
传统的验证技术对于分布式系统来说并不足够,因为验证分布式系统需要考虑到并发、崩溃、网络中断、时钟等问题。并发分离逻辑(Concurrent Separation Logic,CSL)是验证并发系统的一种有效方法,其主要思想是将程序状态分解为多个独立的部分,并使用分离逻辑来描述它们之间的关系,对每个部分都可以单独进行验证。
但是CSL在处理分布式系统时存在局限性。CSL最初是为单机程序设计的,其不能直接处理分布式系统中的并发和通信,例如处理消息传递、网络延迟、节点故障等。
主要设计
本文提出了Grove,是第一个能够处理基于时间租约(lease)的系统的并发分离逻辑库。Grove对并发分离逻辑CSL进行了扩展,以支持具有RPC、租约、复制、重新配置和崩溃恢复的分布式系统。CSL允许单独证明每个函数,甚至每一行代码,而无需显式考虑由于并发、崩溃、恢复等而导致的interleaving情况。这允许Grove增量地证明单个库,而且还可以将多个组件或功能的证明组合成组合系统的单个证明。
在 CSL 中,Grove将系统的状态(state)分解为逻辑上由不同线程拥有的称为资源(resource)的部分,并使用同步原语(如互斥锁)在线程之间转移所有权。Grove归纳了资源和所有权(ownership)的概念来对分布式系统进行推理。其引入了有时间限制的invariant来推理租约,并扩展Crash Hoare Logic来推理分布式系统中的崩溃现象,提供了用于推理append-only logs、单调epoch计数器的抽象,以及经过验证的RPC lib。这使得 Grove 成为第一个能够验证使用时间租约的分布式系统的工具,同时支持验证系统与崩溃恢复、重新配置、并发和不可靠网络的交互。
测试结果
本文使用Grove验证了多个用Go编写的分布式系统组件,其中包括vKV,一个分布式多线程键值存储。vKV支持重新配置、主/备份复制和崩溃恢复,并使用租约lease在任何副本上执行只读请求。
为了证明 Grove 能够验证高性能分布式系统,本文将vKV与Redis进行比较。实验表明vKV的吞吐量是Redis的约67-73%,并且其请求延迟与之相当。
此外,vKV可通过扩展更多核心和备份副本来提升吞吐量,从1台服务器增加到3台服务器时,其吞吐量可达到约2 倍,并且可以在重新配置时安全地执行读请求。
Session 3: Storage
FIFO Queues are ALL You Need for Cache Eviction
Juncheng Yang (Carnegie Mellon University), Yazhuo Zhang (Emory University), Ziyue Qiu (Carnegie Mellon University), Yao Yue (Pelikan Foundation), Rashmi Vinayak (Carnegie Mellon University)One-sentence Summary
本文实现了一种基于FIFO的Cache算法,提供了高可扩展性以及比当前最先进的算法更高的命中率。Background Software cache 在当今的许多系统中被广泛使用(例如Memcached, Linux page cache)。我们可以从如下三个方面来衡量一个cache:
1. Effcient: Miss ratio应该尽可能低,以实现低时延
2. Performant: Cache服务请求时的操作应该尽可能少,以提供高吞吐
3. Scalable: 每秒Cache hit的数量应该可以随着CPU的核心数量一起增长
由于LRU被认为比FIFO更加efficient,许多之前的工作都基于LRU来设计。但是LRU有以下几个缺点:
1. LRU把对象存在双向链表中,其每一个对象都需要两个指针,带来了存储开销
2. LRU中把对象prompt到链表头时需要用锁来保证一致性,导致难以scale
随着cache和backend之间的延迟进一步缩短以及CPU的核数不断上升,Cache的吞吐和可扩展性变得十分重要。之前有很多工作使用FIFO的策略,牺牲Efficient来换取吞吐和可扩展性。本文提出了Simple, Scalable FIFO with three Static queues (S3-FIFO), 实现了高吞吐,高可扩展性的同时还提供了高命中率。
Insight
1. 在cache的工作负载中,对象的热度通常是skewed的,满足 Power-law (e.g., Zipf) 分布
2. 对于任意的 Zipf 请求序列,只出现一次的对象(称作one-hit-wonders)的比例在子序列中远大于整个序列 本文统计了6,594个production trace,one-hit-wonder 在整个序列中的中位占比仅有26%,但是如果我们聚焦于子序列 (大小为总序列的10%) 时,one-hit-wonder 的中位占比提升到了72%。
Design
S3-FIFO利用了quick demoteion的技术来迅速过滤掉one-hit-wonders,阻止他们进入主要的FIFO queue,这样我们的FIFO queue就能更好的用于储存有价值的对象。S3-FIFO主要由三个部分组成:
(1) Small FIFO:大小占总空间的10%,用于迅速过滤掉one-hit-wonders
(2) Main FIFO:大小占90%,用于存储会反复访问的对象
(3) Ghost:储存从small FIFO中驱逐出的对象的元数据,不储存数据。
S3-FIFO的读写流程分别如下:
(1)Cache read.
(2) Cache write.
Evaluation
不同dataset中,各个cache算法的miss rate变化:
对于Zipf的trace本地连接没有有效的ip配置 未修复,各个cache算法吞吐量随CPU核数的变化:
Enabling High-Performance and Secure Userspace NVM File Systems with the Trio Architecture
Diyu Zhou (EPFL), Vojtech Aschenbrenner (EPFL), Tao Lyu (EPFL), Jian Zhang (Rutgers University), Sudarsun Kannan (Rutgers University), Sanidhya Kashyap (EPFL)
背景
非易失内存(NVM)结合了存储的持久性和内存的高性能和字节寻址,为高性能文件系统提供了新的机会。用户态NVM文件系统具有以下优点:

1. 应用程序通过LibFS,使用内存指令直接访问NVM来执行文件系统操作,最小化软件开销;
2. 应用程序能够定制自己的LibFS来针对语义优化,进一步提高性能。
但是,上述优点也带来了文件系统安全性上的挑战。由于直接访问,恶意程序能够绕过检查,破坏文件系统的元数据。为了解决该问题,需要引入一个可信实体来检查元数据完整性。但是,由于LibFS的可定制,不同文件系统的数据结构可能不同,难以被可信实体解析。
关键思路
本文提出TRIO,在保留用户态NVM文件系统两个优点的同时,实现元数据完整性保护。文章的关键洞察是,文件系统状态可以被划分为核心状态和辅助状态。其中,核心状态(如inode,data page)是文件系统的基础,而辅助状态(如in-memory cache, block bitmap)由核心状态决定,并可以从核心状态重建。基于这一洞察,TRIO规定核心状态的布局和数据结构,并允许各个组件维护自己的辅助状态。
设计
如下图所示,TRIO由三部分组成:内核访问控制模块、应用私有的LibFS、可信用户态完整性检查模块。其中,内核访问控制模块决定LibFS可以访问哪些共享的文件系统资源(如NVM page和inode)。每个LibFS实现一组完整的文件系统设计,直接访问文件的核心状态,并利用私有的辅助状态提供非特权的私有定制功能。为了保证状态的安全共享,TRIO阻止LibFS同时更新文件。当一个LibFS访问被另一个LibFS修改过的文件时,完整性检查模块会确认该文件的核心状态是否有效。然后,LibFS再根据该文件的核心状态重建对应的辅助状态,从而安全地访问该文件。
基于TRIO,文章设计了一个POSIX-like的文件系统:ARCKFS。该文件系统充分利用NVM直接访问的优势,设计了高效的数据结构、可扩展的NVM数据访问引擎和细粒度的并行化,从而获得了数据和元数据操作的低延迟、高吞吐、高可扩展。
文章进一步在ARCKFS的核心状态基础上,定制了为小文件访问优化的KVFS和为深目录访问优化的FPFS。这些文件系统改变了接口和关键元数据结构,从而实现了针对应用的高度优化。
测试
测试表明,ARCKFS的LevelDB性能相对于其他文件系统提高了3.1x至17x,并且在扩展性微基准测试上取得了两个数量级的提高。KVFS和FPFS的性能在ARCKFS的基础上进一步提高了1.3x。
Project Silica: Towards Sustainable Cloud Archival Storage in Glass
Patrick Anderson (Microsoft), Erika Blancada Aranas (Microsoft), Youssef Assaf (Microsoft), Raphael Behrendt (Microsoft), Richard Black (Microsoft), Marco Caballero (Microsoft), Pashmina Cameron (Microsoft), Burcu Canakci (Microsoft), Thales de Carvalho (Microsoft), Andromachi Chatzieleftheriou (Microsoft), Rebekah Storan Clarke (Microsoft), James Clegg (Microsoft), Daniel Cletheroe (Microsoft), Bridgette Cooper (Microsoft), Tim Deegan (Microsoft), Austin Donnelly (Microsoft), Rokas Drevinskas (Microsoft), Alexander Gaunt (Microsoft), Christos Gkantsidis (Microsoft), Ariel Gomez Diaz (Microsoft), Istvan Haller (Microsoft), Freddie Hong (Microsoft), Teodora Ilieva (Microsoft), Shashidhar Joshi (Microsoft), Russell Joyce (Microsoft), Mint Kunkel (Microsoft), David Lara (Microsoft), Sergey Legtchenko (Microsoft), Fanglin Linda Liu (Microsoft), Bruno Magalhaes (Microsoft), Alana Marzoev (Microsoft), Marvin McNett (Microsoft), Jayashree Mohan (Microsoft), Michael Myrah (Microsoft), Trong Nguyen (Microsoft), Sebastian Nowozin (Microsoft), Aaron Ogus (Microsoft), Hiske Overweg (Microsoft), Antony Rowstron (Microsoft), Maneesh Sah (Microsoft), Masaaki Sakakura (Microsoft), Peter Scholtz (Microsoft), Nina Schreiner (Microsoft), Omer Sella (Microsoft), Adam Smith (Microsoft), Ioan Stefanovici (Microsoft), David Sweeney (Microsoft), Benn Thomsen (Microsoft), Govert Verkes (Microsoft), Phil Wainman (Microsoft), Jonathan Westcott (Microsoft), Luke Weston (Microsoft), Charles Whittaker (Microsoft), Pablo Wilke Berenguer (Microsoft), Hugh Williams (Microsoft), Thomas Winkler (Microsoft), Stefan Winzeck (Microsoft)
这是一篇非传统的SOSP论文,介绍了基于玻璃的存储设备设计,以及在微软内部用于archive的尝试。
当前长期数据归档存储的需求不断增长,但是现有的HDD硬盘、磁带等基于磁介质的存储设备都无法保证可持续性及低成本。其主要原因在于磁介质寿命有限,数据随着时间的推移会发生损坏,因此需要定期地对数据进行检查、迁移等操作,这导致即使用户不访问这些数据,数据存储的开销也在随时间不断增加。
Project Silica首次尝试将数据存储至石英玻璃中。石英玻璃是一种低成本且耐用的存储介质,允许对数据进行一次写入后多次读取,且数据可保存上千年而不发生损坏。石英玻璃的这一性质意味着在数据一次写入之后,后需不需要反复对其进行校验和迁移,这可以大大降低存储的成本开销及碳排放量。Project Silica使用不同的技术来写入和读取数据:使用超快飞秒激光器进行写入,使用常规光进行偏振敏感显微镜读取。
Project Silica采用软硬件协同设计的方式,系统的软硬件完全分离,可以实现系统每个部分的弹性和最大化利用率,而不牺牲可维护性和灵活性。软件部分包含数据的编码、解码和校验过程。值得注意的是,数据的解码利用了机器学习的方式,作者称使用图像识别的方式进行解码可以比传统的信号处理方式具有更高的精确性。在硬件部分,Project Silica将不同的玻璃盘片组织成了一个类似图书馆的结构,其中有自由漫游的穿梭器可以任意访问不同的盘片,穿梭器的数量可以根据负载进行调整。
作者对Silica进行数字孪生模拟测试,并与系统原型进行交叉验证后显示,一方面,Project Silica在不同的读吞吐下都能满足用户的SLO要求(即查询请求的时间要求);另一方面,系统的设计可以实现驱动器的高利用率。
RackBlox: A Software-Defined Rack-Scale Storage System with Network-Storage Co-Design
Benjamin Reidys (University of Illinois Urbana Champaign), Yuqi Xue (University of Illinois Urbana Champaign), Daixuan Li (University of Illinois Urbana Champaign), Bharat Sukhwani (IBM Research), Wen-mei Hwu (University of Illinois Urbana Champaign), Deming Chen (University of Illinois Urbana Champaign), Sameh Asaad (IBM Research), Jian Huang (University of Illinois Urbana Champaign)
背景
软件定义的基础设施已经成为数据中心管理的新标准,能够灵活、迅捷地为应用程序适配硬件资源。软件定义网络(SDN)允许用户使用可编程交换机来配置和管理网络资源。类似地,软件定义存储(SDS)也被提出,代表性的例子是软件定义闪存(SDF)。SDF使得上层软件能够管理底层存储芯片,从而优化性能和资源利用率。SDN和SDF都有可编程的控制面和数据面,以便开发者定义和实现资源管理策略和调度策略。但是,在数据中心里,SDN和SDF是被分开管理的。尽管这符合分层设计原则,但是SDN和SDF之间缺少协同会阻碍端到端性能的优化。虽然 SDN 和 SDF 都能尽最大努力实现其服务质量,但它们不能共享状态,也缺乏用于存储管理和调度的全局信息,因此应用程序要实现可预测的端到端性能十分困难。先前的研究提出了各种软件技术,但由于将底层固态硬盘视为黑盒,仍然很难在整个机架上实现可预测的性能。关键思路 由于 SDN 和 SDF 有着相似的架构——控制平面负责管理可编程设备,数据平面负责处理 I/O 请求,因此可以集成并共同设计 SDN 和 SDF,并重新定义它们的功能,以提高整个机架级存储系统的效率。设计 本文提出了一种名为 RackBlox 的新型软件定义架构,以协调的方式利用 SDN 和 SDF 的功能。RackBlox的架构如下图所示。
RackBlox的主要设计点如下:
(1)解耦存储管理:受限于可编程交换机上有限的硬件资源,RackBlox将SSD虚拟化、设备层面映射、本地磨损均衡等关键功能部署在存储节点上,将vSSD层面映射表维护在交换机数据面。该映射表分为两部分,如下图所示。该表包含了I/O调度和GC协调所需的关键信息。第一张表记录了vSSD当前的GC状态,以及对应的replica vSSD ID。第二张表记录了vSSD当前的GC状态,以及所在的Server IP。
(2)协同I/O调度:传统方法缺少SDN和SDF之间的状态共享,无法准确感知系统状态,可能产生错误的调度决策。RackBlox将端到端延迟分为(1)请求发送到存储节点的网络时延、(2)存储队列时延(3)回复返回客户端的时延,并分别使用可编程交换机提供的Inband Network Telemetry、存储队列跟踪、历史平均值预测的方式获取上述时延。根据这一信息,RackBlox实现高效率的I/O调度,降低请求的端到端时延。
(3)协同GC:RackBlox在vSSD的多个replica之间协调GC的时机,保证每一时刻都存在没有做GC的replica。RackBlox在交换机中维护当前每个vSSD的GC状态,并将操作转发到没有做GC的vSSD,从而避免GC对性能的影响。
(4)机柜层磨损均衡:RackBlox分别实现全局磨损均衡和本地磨损均衡。本地磨损均衡跟踪单个节点上多块SSD的擦除次数,进行均衡调度。全局磨损均衡跟踪每台机器的平均擦除次数,并交换磨损最高和最低的机器数据,从而进行全局均衡。
测试
测试显示,RackBlox 最多可将端到端 I/O 请求的尾延迟降低 5.8x,并能在不引入大量额外性能开销的情况下实现固态硬盘机架的统一使用寿命。
Session 4: Cloud
Cornflakes: Zero-Copy Serialization for Microsecond-Scale Networking
Deepti Raghavan (Stanford University), Shreya Ravi (Stanford University), Gina Yuan (Stanford University), Pratiksha Thaker (Carnegie Mellon University), Sanjari Srivastava (Stanford University), Micah Murray (UC Berkeley), Pedro Henrique Penna (Microsoft Research), Amy Ousterhout (UC San Diego), Philip Levis (Stanford University and Google), Matei Zaharia (UC Berkeley), Irene Zhang (Microsoft Research)
本文基于网卡的scatter-gather接口,实现了一种zero-copy的序列化机制,并与传统的基于copy的序列化方式结合,灵活选择两者中性能更好的策略。
背景与挑战
scatter-gather是一种较为新颖的网卡接口,程序可以通过他直接向网卡发送一系列内存块的地址和长度,随后网卡硬件会异步的通过DMA读取这些内存块,连接成一段完整的字符流,并完成发送。与之对应的copy方案则是由软件进行内存块的复制,首先申请一个buffer,然后依次把需要发送的内容拷贝进buffer中,最后再调用网卡发送这一buffer。scatter-gather可以避免拷贝进buffer这一过程,因此被称为Zero-Copy。然而这样序列化方案带来了一些新的挑战:
1. scatter-gather方案在需要传输的数据块较小时,性能不如传统的copy方案。需要灵活的在两个方案间进行选择。
2. 由于发起scatter-gather后,硬件会在随后的某个不确定的时间点发起DMA,获取内存内容。因此需要避免应用free对应的内存区域,还需要避免应用对相应区域进行修改。
3. 由于scatter-gather只能发生在允许DMA的,被kernel pin住了的内存区域中。因此需要序列化器高效的判断一个传入的object是否可以使用scatter-gather发送。
设计
1. 选择策略的启发式算法:Cornflakes通过判断object的一个field是否大于某个指定尺寸,来决定通过zero-copy还是copy策略来传输这一个field。例如下图的list包含val1-3这三个element,只有val1的尺寸达到了使用zero-copy的阈值,因此header和val2 val3会通过普通的copy方式提前构造成一个数据块。随后会利用NIC的scatter-gather功能,收集这个数据块和val1对应的数据块,在网卡内合成成一条消息进行发送。
2. Ref-counted buffers (RcBuf) :为了保证内存内容的一致性本地连接没有有效的ip配置 未修复,Cornflakes实现了一个自带引用计数器的RcBuf,每当其指针被克隆,计数器就会增加。而包括DMA完成在内的指针销毁会减少计数器。当计数器清零时才会自动释放这段内存,避免了应用中的free过早释放内存。
3. 修改内存分配器:Cornflakes要求应用手动修改内存分配代码,以实现在DMA区域中分配某些特定对象。
4. 内存安全性:Cornflakes要求应用不可以在DMA期间原地修改将要被发送的数据块,只能在复制后进行修改。
性能测试
在Twitter cache trace中,Cornflakes比FlatBuffers和Protobuf实现了15.4的吞吐性能提升
下图的breakdown说明了Cornflakes在各流程中均有效的降低了时延。
下图实验说明了通过启发式算法结合copy策略和zero-copy策略,实现了优于单纯使用两个方案S的性能。
Understanding Silent Data Corruptions in a Large Production CPU Population
Shaobu Wang (Tsinghua University), Guangyan Zhang (Tsinghua University), Junyu Wei (Tsinghua University), Yang Wang (Meta/The Ohio State University), Jiesheng Wu (Alibaba Cloud), Qingchao Luo (Alibaba Cloud)
背景与问题 CPU故障可能导致应用程序发生错误,这些错误分为两类。一类错误会立即导致崩溃或异常。另一类错误可能会引入错误的数据(例如,不正确的计算结果甚至数据丢失),但是这类错误不会立即被检测到。第二类由处理器故障引起的错误称为“静默数据损坏”,简称为SDC。CPU 出现的SDC在生产环境中出现的频率很低,但是不可忽略。例如,阿里云的少数CPU偶尔会给出错误的校验和计算结果。这些不正确的信息会误导云应用程序得出请求数据已损坏的结论,从而频繁触发重复请求,损害了整体性能。现有对SDCs的研究主要分为三类,但是这三类对于SDC的研究都非常有限:
(1)理论上说明了SDCs的存在,但没有研究具体误差
(2)通过人工注入的方式代替自然产生的SDCs,研究SDCs的影响和容限技术
(3)提供了真实世界中CPU SDC案例的简要数据,但缺乏对故障率、软件症状、发生模式等的详细测量和分析
基于上述问题,本文对大型生产系统中的CPU SDCs进行了研究,包括来自14个国家28个数据中心的数百个集群的100多万个CPU,并提出了Farron,一种有效的减缓SDC的方法。本文也是第一次在大规模生产环境中定量评估和系统分析CPU SDC现象的工作 核心观察 本文对于SDC的研究使用了芯片制造商提供的工具链,该工具链会检测与云工作负载相关的SDCs。其中包括633个测试用例和一个框架。测试框架会驱动这些测试用例,并检查是否出现了SDCs。
设计
本文为了说明观察结果如何有助于缓解SDC,提出了一个具体的战略,称为Farron,并和阿里云的现有策略进行比较。阿里云使用的现有策略通过主动运行SDC测试来减少SDC的影响,SDC测试在生产前和生产中会在每三个月进行一次。在每一轮测试中,所有的测试用例都是顺序执行的,并且分配了相同的测试资源。如果其中一个核心被检测出存在问题,阿里云将弃用包括这个核心的整个处理器。Farron工作流的工作流会在三种状态下运行:预生产、在线和可疑状态,如下图所示。在预生产状态期间,将使用充足的资源进行SDC测试。在线状态下,用户应用程序在经过SDC测试验证的核心上运行,并在Farron控制的触发条件下工作。在线状态下会定期进行SDC测试。如果SDC测试失败,Farron会进入可疑状态,将针对可疑处理器进行深入的SDC测试,并根据测试结果分析调整可靠资源的配置。
基于上述观察,Farron存在三个特性:
1. 自适应温度边界,Farron区分了冷却设备操作和工作负载退回的温度边界,并使工作负载退回的边界自适应。Farron采用一个窗口来跟踪最近的温度监测记录,如果窗口内超过一半的温度记录超过当前边界,则提高工作负载退回的温度边界,表明该温度是处于应用的正常工作范围内。如果不到一半的温度记录超过当前边界,就会触发工作负载回退,直到温度低于边界为止。
2. 注重效率的SDC测试,本文对测试用例建立了三个不同的优先级级别:基本的、活跃的、可疑的。“基本”优先级被分配给在大规模测试中没有检测到错误的测试用例。"活跃"优先级是分配给已经成功识别出错误的测试用例。“可疑”优先级仅分配给在当前处理器的核心上检测到错误的测试用例。
3. 细粒度处理器屏蔽,Farron通过对已确定存在缺陷的核心进行适当的测试,积累了具有"可疑"优先级的测试用例。通过对这些"可疑"测试用例进行足够数量的SDC测试,Farron会继续验证剩余核心的功能。如果在一个处理器中发现超过两个有问题的核心,Farron会废弃整个处理器。相反,Farron只会屏蔽该有问题的核心并继续正常使用其他核心。
测试
测试结果说明,Farron在一轮测试中SDC的覆盖率高于基线(阿里云现有策略)。在开销方面,Farron的平均一轮常规测试持续时间为1.02小时,而在基线中为10.55小时,开销也小于阿里云现有策略
XFaaS: Hyperscale and Low Cost Serverless Functions at Meta
Alireza Sahraei (Meta Platforms, Inc), Soteris Demetriou (Imperial College London, Meta Platforms), Amirali Sobhgol (Meta Platforms, Inc), Haoran Zhang (University of Pennsylvania), Abhigna Nagaraja (Meta Platforms, Inc), Neeraj Pathak (Meta Platforms, Inc), Girish Joshi (Meta Platforms, Inc), Carla Souza (Meta Platforms, Inc), Bo Huang (Meta Platforms, Inc), Wyatt Cook (Meta Platforms, Inc), Andrii Golovei (Meta Platforms, Inc), Pradeep Venkat (Meta Platforms, Inc), Andrew McFague (Meta Platforms, Inc), Dimitrios Skarlatos (Carnegie Mellon University, Meta Platforms), Vipul Patel (Meta Platforms, Inc), Ravinder Thind (Meta Platforms, Inc), Ernesto Gonzalez (Meta Platforms, Inc), Yun Jin (Meta Platforms, Inc), Chunqiang Tang (Meta Platforms, Inc)
一篇非常细致的工业界的文章,较为详细地描述了Meta内部FaaS平台的实现。
Motivation
这篇文章主要聚焦在Meta FaaS系统面临的几个问题:
1. 冷启动时延长。老问题无需赘述
2. 用户负载(Load)的变化性(波动)和skewness的问题。这就导致资源分配很难达到完美,在负载高峰容易导致性能过载,在负载低峰则可能导致资源浪费
3. 对downstream services的影响。例如一个function可能大量访问数据库导致需要访问数据库的其他service崩溃。对concurrency limit单独进行限制,也非常考验设置的准确性:limit设的太高仍然会导致崩溃,设的太低则会造成FaaS和database的资源浪费。
Design
XFaaS应用了多个不同层面的设计思路来解决上述三个问题。这里high level地总结一下:为了解决冷启动时延的问题,XFaaS主要应用以下几个优化:
1. XFaaS指定一些server来固定运行某个编程语言(如PHP),并将该语言的所有函数的最新代码push到这些server的local SSD上。这些server上,该语言的runtime持续运行,这样仅需要从SSD上load函数代码即可运行对应的函数
2. XFaaS让多个函数运行在同一个进程内,使用Bell-La-Padula的方法来保证数据隔离
3. XFaaS使用coopoerative JIT compilation,即当一个函数的新版本在一个server上运行时,XFaaS会将这台server上实时编译的JIT code发送到其他server上。为了提高JIT code cache命中率,XFaaS只会让一个server接收所部分函数的JIT code,并且根据load情况来适时调整接收哪些函数的JIT code
为了解决用户负载波动的问题,XFaaS:
1。XFaaS倾向于平时使用尽可能少的资源(即不足以支撑峰值负载),然后处理突发的overload情况。XFaaS的函数都具有优先级(criticality)和deadline的设置,当复杂达到capacity时,可以容忍delay的函数就会被推迟运行。
2. XFaaS在多个datacenter regions之间做负载均衡
3. XFaaS为每个函数设置了quota(通常是RPS),在超过quota时进行节流。
4. XFaaS允许caller设置future execution start time,这样可以允许负载在可预测的情况下被均摊
通过上述方法,XFaaS能够将负载变得更加均匀,如图:
为了解决造成downstream service过载的情况,XFaaS使用adaptive concurrency control,使用一个global的中心化的资源管理系统,来进行资源隔离。同时,downstream service也可以发送back-pressure signals给XFaaS,XFaaS使用类似于TCP阻塞控制的方法来对函数执行进行调整和限制。
下图为XFaaS的high-level架构:
Evaluation
这部分主要包括XFaaS实际运行的一些指标来说明上述设计的效果,举几个例子:例如CPU资源利用率,XFaaS能够将资源利用率保持在一个较高的值:
例如cooperative JIT compilation能够快速让函数运行达到较高性能:
Pushing Performance Isolation Boundaries into Application with pBox
Yigong Hu (Johns Hopkins University), Gongqi Huang (Johns Hopkins University) Peng Huang (University of Michigan)
之前提到性能隔离主要是应用之间的性能隔离,比如serverless的不同实例之间。本文主要考虑的是应用内部的interference。
Motivation
同一个应用内部也会发生严重的资源interference造成性能下降,例如:mysql内部存在buffer pool来缓存table和index数据。然而,一些backup task可能会使用mysqldump指令,这会使用大量的buffer pool例的block,造成其他任务的性能下降。
Challenge
1. 现有的基于硬件隔离的方法显然无法应对这种软件资源(如上例中buffer pool中的block)上的竞争。
2. 简单的drop request的方法也无法应对,因为很多时候并不知道是什么request导致了这样的interference(故障根因难),且很多造成intereference的task是后台task
3. 简单限制资源,如Mysql在user level层面限制资源(如query数)也只能应对overload的情况,无法应对少量request时造成的interference的情况。
Design
不同应用interference是由不同的软件资源竞争导致的。用什么抽象可以抽象出各种应用的资源竞争呢?pBox使用state event来进行总结。pBox主要总结了四种state event,如下图所示:
本文设计了一个新的抽象,pBox,作为资源隔离的粒度。pBox可以是request level的(即一个request一个pBox),也可以是user connection level的(在建立连接时创建pBox,断开连接时销毁pBox,如下图所示)。
当pBox被定义好后,pBox就可以提供应用的信息,记录state event,然后传递给OS的pBox manager进行管理,从而起到对pBox做trace的作用。
如何找到state event呢?作者发现state event通常和一些preemption类的syscall相关,例如sleep, futex, select之类,所以作者建议developer可以去找syscall,人工判断是否会存在state event,然后显式地使用pBox api告诉pBox manager发生了state event。根据收集到的state event信息,pBox主要通过几个算法来解决两个挑战:
1. pBox manager如何提前观测出pBox马上要被interference了?
2. 观察到即将发生的intereference之后,pBox manager如何做出决策来避免interference带来的性能下降?
对于第一个挑战:pbox主要依靠历史的等待时间,即PREPARE到ENTER之间的间隔,来判断是否马上要interference了。具体主要是考虑等待时间和执行时间的一个比例(公式略)。如果一个resource的holder pBox,其waiter中存在即将发生interference的pBox,那么这个holder被认为是noisy pBox,而waiter认为是victim pBox。
对于第二个挑战:对于noisy pbox,pbox manager给它加一个delay让它slow down,这样避免其干扰victim pbox。并且,添加delay的timing需要是noisy pbox将软件资源释放完成后才可以。对于delay的长度,pbox同样有一个算法去确认,这里略。作者还讲到有个静态的analyzer用来分析、帮助应用添加pbox API。这里略。作者声称只需要少量代码就可以解决这个问题:
Evaluation
这里pBox能够显著优化interference情况下的性能:
本期内容由以下作者共同完成:


一本")




")
