
一般反作弊主要业务流程:
听不懂?对了,我们继续往下看,在了解这个模型之前,还需要补充一些专业知识!
我们常见的跨境电商作弊方式:
机器作弊:刷赞、任务分发、流量劫持
人为作弊:qq群/水军,直接人工,诱导
电子商务中常见的作弊方式:
刷单、刷信用、刷好评、专业差评
判断广告欺诈所涉及的点击类型类别:
1、根据是否以寻找产品和服务为目的;
2、是不是恶意的,是不是真的。
(CPC是按点击计费方式,CPA是按交易点击计费)
电商平台常见的点击行为分为四类:
无效点击(无意转化,只是浏览);
恶意点击(必须识别);
转化点击(真正的意图点击);
错误(不是为了寻找产品的目的,比如内部人员的点击,需要识别)。
点击人群:
任务:员工、广告商本身、竞争的销售机构、爬虫;
恶意点击:同行、同行、附属网站、机器。
反作弊策略响应框架:
数据层:鼠标轨迹行为、指纹数据、案例库、行为数据;
特征层:离散索引、连续索引;
行为识别层:点击识别模型、异常监控模型、流量识别模型、关系图模型、人群识别模型;
战略响应层:规则。
看完上面一些专业术语的不好的补充,我们来看看亚马逊是如何监控刷赞的:
三层监控指标体系,预警:
运营指标监控:投诉率、转化率、碰撞率/频率、消费率、合格率;
规则监控指标:拦截率、准确率、覆盖率;
异常监控指标:IP维度、cookie维度、计费名称维度、广告维度、设备维度、鼠标轨迹维度
分类监控,分级响应:
1、监控情况采用四级响应机制;
2、红色:非常严重,需要自动化的短期策略,比如临时黑名单机制
3、橘子:比较严重,短信举报。要求在4小时内完成分析并采用短期策略压制,后续进一步处理
机器学习在反作弊应用中的几个案例:
如关联规则、决策树模型:策略挖掘——自动规则抽取
确定建模问题:自动发现规则,辅助策略设计;
申请:规则挖出,上线到线下防作弊系统;
评价指标:支持度、置信度、覆盖率、拦截率
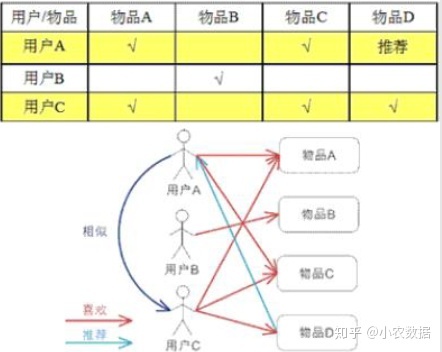
有一种算法叫“千人千面算法”。首先,我们来看看作弊的几个方面:
1、同一个IP
也就是说,你的朋友都买不起你的东西,因为你们两个迟早会见面的。当两个人相遇时,他们会遇到IP。所以,买你宝物的人,你们两个的IP永远是见不到你,也就是说你们两个永远都见不到了!
2、性别
如果你的淘宝店卖衣服,而且时不时有男买家在你家买这个宝贝,你觉得这很正常,你男朋友买有什么问题?我男朋友的号码怎么了? ?但算法认为你在作弊!你在作弊!
3、行为
这种行为意味着,如果您在购买婴儿,您没有特定的流程。大家帮你刷流量都是搜索关键词,找到你的宝贝,点击收藏,加入购物车,然后下单,你觉得不可能,更别说算法了!
4、年龄
你的淘宝店卖丝袜,好吧,你男朋友可以给你买,但是你要找的人都是40多岁的。谁40岁的男人帮儿媳网买丝袜?最棒的是你找18-30岁的女性刷宝宝是很正常的!
5、能力
支付宝都是实名认证,我们的很多产品都是由支付宝控制的。你卖意大利名牌古驰,却总找一些大学生帮你付账。这一定是个问题。学生能力有限。没有工作,买这么贵的皮具肯定有些问题!
使用关联规则检测欺诈行为
近日,发现我们平台上的一些内容提供商使用一些非法手段欺骗自己的付费内容。以非常优惠的价格从其他渠道购买代金券,在平台上消费自己的项目内容,从而获得结算分成和成本之间的差额。
由于这个问题需要进一步关注和监控,我也在考虑一些检测方法,其中一种是尝试分析本文介绍的数据挖掘中基于关联规则的算法。关联规则的算法原理这里不再赘述。
利用关联规则的一个众所周知的例子是沃尔玛啤酒尿布在客户的购物篮中查找经常同时购买的物品的案例。这种情况类似于啤酒尿布的情况。主要是因为内容提供者使用低价购买的客户账号购买了自己的产品,但根据以下分析,这种情况下可能存在强关联效应:
(1)购买同批次的内容产品会节省作弊成本。
(2)由于客户账号数量有限,会出现一个客户账号购买很多内容的现象。
与沃尔玛的案例不同的是,沃尔玛的案例是探索正面和正面的事件。在这种情况下,就是发现负面和负面事件。以沃尔玛为例,要求事件的支持度要高,即事件只有频繁发生才有意义,置信度只要不太高就适当。支持度不能要求很高。相反,置信度必须比较高,即当某个时间发生时,另一个相关时间也发生的概率必须很高。
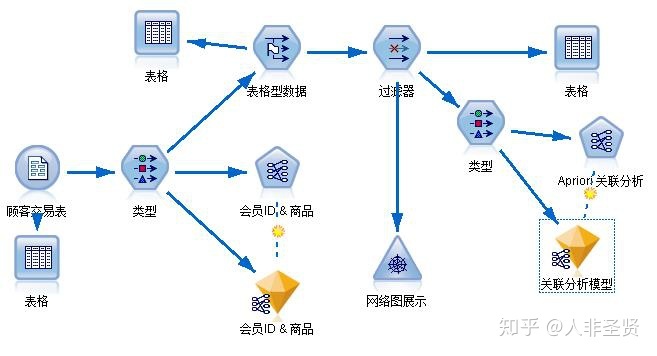
通过初步假设,提取某一天的客户订单数据进行建模。模型如下:
关联规则模型设置如下:
由于使用的是交易数据格式(根据交易明细记录,特点是一个客户ID可以有多条数据),所以需要勾选使用交易格式选项。另外,由于本例需要对所有CASE进行关联分析,所以数据没有分区。
此示例需要如上所述的低支持和高置信度设置。因为这个例子只需要找到任意两个内容项的关联,所以只设置了最大前件数为1。
最终模型结果如下:
从结果模型可以看出,两个内容项之间的相关度可以高达100%,即如果用户购买了某个内容项,那么100%的用户会购买另一个内容物品。这很棘手,而这条规则正是我要寻找的。
虽然对这些规则的支持度很低,但作弊是一种反常现象,不能要求很高的支持度。
将模型导出为文本,并组织这些内容项。通过对这些项目的购买清单的观察和分析,发现这些内容项目中产生的订单中,95%以上的订单有很强的作弊嫌疑。关联模型对此类作弊行为有很强的检查能力。
现阶段只尝试了模型的可行性,没有考虑模型的部署。本文仅介绍这一点,希望对朋友有所启发。
使用反作弊算法检测欺诈行为
以亚马逊的Review算法为例:
1.已验证购买。直接评论已经死了。这时候刷直接评论不仅没有意义,还可能出现如上群聊所示的“好评排名会下降”的情况。
所以如果你想刷,就刷VP。还记得年初的封号风波,这些卖家大多是因为虚单被姐夫“秋后结账”;船长在之前的分享中给大家提了一个欺诈建议,模仿真实的购买行为。
亚马逊希望所有评论都是诚实的,并且在他的监控中,如果我们能够“模拟”,我们就可以避免受到惩罚。具体如何模拟真实的购买行为来刷单,我们将根据以下影响因素一一分析。
2.评论的频率和间隔。评论频率越高,间隔越短,权重越高。
如果产品不断获得正面评价,则表明该产品很受欢迎。也就是说,你需要根据自己的产品特性来规划刷单的频率、留下评论的频率、以及评论之间的时间间隔。当然,时间和频率的控制也需要考虑到产品的销售周期。比如网站冬天不能继续订泳装和留言吧?
既然涉及到时间和频率,大家在刷单和评论的时候需要注意。一般情况下,在买家的真实购买行为中,账户平均交易量最多为每月10-20单,评论数不超过10%。 ,在越来越严苛的评论政策下,最好不要超过 5%。
也就是说,你在选择资源刷单,或者组建自己的扫货团队时,除了要规划好房源评论的时间和频率外,还需要根据交易状态选择合适的人选,发表评论的时间和频率。买家帐号。
3.字数、内容和比例,即评论内容的质量。刷卡的需求越大,刷单者的胃口也越大。卖家经常花很多钱却被一个随机的“好”或“精彩”的五星级敷衍了事。在新算法下,这种低价值的评论对权重排名没有帮助。
评论由专家审核。亚马逊希望评论能够真实反映产品的情况,为买家提供参考,避免不良的购物体验。客观、丰富、完整的评论内容可以增加权重。
如今,买家和姐夫都应该认真对待审查评论的标准。站在真实买家(产品买家、用户)的角度,客观评价这个产品,甚至不是全五星评价;根据客服提供的依据,还需要有有趣幽默的评论,并且数量要在最近10条评论总数的一定比例,比如每10条评论至少有1-2条有趣的评论(包括正面、中度和负面评论)等等。
如果不知道从评论的内容入手,可以查看竞争对手的评论,选择内容丰富、大量“有帮助”的顶级VP评论进行模仿。记住要模仿,不要抄袭。至于有趣的内容,最好搭配相关且有趣的图片或视频,尤其是童装、玩具等婴儿用品。可以使用的材料更多。
4.“有用”评论的数量。这是一个陷阱!点击“有帮助”(俗称“赞”)也是需要买家账号的,但如果不小心使用了一些“质量差”的买家账号刷点击,那就完了。
首先,使用优质的买家帐号。船长在上面也提到,真实买家账户的平均交易量每月最多10-20条,评论数不超过10%。此外,还要注意账号的年龄和使用习惯。一般来说,越老的账号越好,但是老僵尸账号被拒;并且还要防止关联买家账号,关联条件和卖家账号一样。
接下来,使用这些优质买家帐号来模仿真实买家的喜好。从登录买家账号到点赞,一般需要经过以下几个步骤:
①搜索:通过亚马逊前台输入你的产品关键词,或者通过你的产品对应的分类搜索,或者通过品牌名称搜索(不建议小卖家直接搜索品牌名称)。
2 比较:逐页查找您的列表。在搜索过程中,您可以点击其他几个人的listing浏览几秒钟,翻阅评论和问答,在两三个产品页面上停留更长时间。
③点赞:通过一些操作找到你的产品,进入评论区后不要立即找到目标评论点赞,可以在首页或前几页浏览评论,打开折叠回复查看,点击图片或视频,甚至离开产品页面并返回浏览并喜欢它。
5.Review original star score,即原始Review星级。这个影响因素已经不能再改变了,但不代表原来的分数现在就不能提高了。它可以从其他因素进行优化。
6.详情页的点击次数、买家离开详情页的次数、买家再次返回详情页的比率。其实就是按照买家正常下单的逻辑,同理心,你网购的时候怎么操作,按照类似的顺序和逻辑刷单就好了。
除了评论算法的变化,亚马逊还更新了《评论服务条款》以进一步保障评论的真实性,同时还制定了处罚政策。简而言之,操纵评论会产生严重后果。
这时候再回去看看我们的第一张流程图,大致就能明白原理了。
内容来源:
1.
2.
3.
4.
文章内容由作者创作,作者对内容的真实性、准确性和合法性负责。楚海逸倡导尊重和保护知识产权。未经作者和/或本网站许可,不得复制、转载或以其他方式使用本网站内容。如果您发现本站文章存在版权问题,请联系chuhaiyi@baidu.com,我们将及时核实处理。文章来源:卖家之家,本文为作者独立观点,不代表易海易立场。








