
Excel 和 Python 都是数据分析中常用的工具。本文将使用动态图(Excel)+代码(Python)来演示这两个工具如何实现数据的读取、生成、计算、修改、统计、采样、搜索、可视化、存储等数据处理中的常见操作!
本文内容较长,喜欢的记得关注、点赞、收藏。
【注】文末提供技术交流群
数据读取
说明:读取本地Excel数据
Excel
Excel需要打开目标文件夹读取本地数据,选择文件打开
熊猫
Pandas 支持读取本地 Excel 和 txt 文件,也支持只用一行代码直接从网页读取表格数据。例如,要读取上述本地 Excel 数据,使用 pd.read_excel("sample data.xlsx")
数据生成
描述:生成指定格式/数量的数据
Excel
以生成一个10*2 0-1均匀分布的随机数矩阵为例,需要在Excel中使用rand()函数生成随机数,手动拉取指定范围
熊猫
在 Pandas 中,可以结合 NumPy 生成由指定随机数(均匀分布、正态分布等)生成的矩阵。例如,要生成一个10*2 0-1 均匀分布的随机数矩阵,可以使用一行代码:pd.DataFrame (np.random.rand(10,2))
数据存储
说明:将表中的数据存储到本地
Excel
在 Excel 中,您需要单击保存并设置格式/文件名
熊猫
在Pandas中可以使用pd.to_excel("filename.xlsx")将当前工作表保存到当前目录,当然也可以使用to_csv保存为csv等其他格式,也可以使用绝对路径指定保存位置
数据过滤
描述:根据指定要求过滤数据
Excel
使用我们之前的示例数据,在Excel中过滤掉薪水大于5000的数据的步骤如下
熊猫
在Pandas中有赞每日数据分析,可以直接对数据框进行条件过滤,例如也可以进行单个条件(salary大于5000)可以使用df[df['salary level']>5000]进行过滤,如果使用多个条件过滤只需要使用&(and)和|(or)操作符即可实现
数据插入
说明:在指定位置插入指定数据
Excel
在 Excel 中,我们可以将光标放在指定的位置,然后右键添加一行/列。当然我们也可以在相加的时候对数据进行一些计算,比如我们可以使用IF函数(=IF(G2>10000,"High","Low")),将大于10000的工资设置为高,将低于10000的工资设置为低,在末尾添加一列
熊猫
在pandas中,如果我们不使用自定义函数,我们可以使用cut方法来实现同样的操作
bins = [0,10000,max(df['薪资水平'])]
group_names = ['低','高']
df['new_col'] = pd.cut(df['薪资水平'], bins, labels=group_names)
数据删除
说明:删除指定的行/列/单元格
Excel
在 Excel 中删除数据非常简单。找到要删除的数据,右键删除,比如删除刚刚生成的最后一列。
熊猫
pandas中删除数据也很简单,比如删除最后一列,使用del df['new_col']
数据排序
描述:按照指定的要求对数据进行排序
Excel
在Excel中,可以点击排序按钮进行排序,例如按照工资从高到低对样本数据进行排序,可以按照以下步骤进行
熊猫
pandas中可以使用sort_values进行排序,使用ascending可以控制升序和降序。例如,要根据薪水从高到低对样本数据进行排序,请使用 df.sort_values("salary level", ascending=False, inplace=True)
缺失值处理
说明:按规定要求处理缺失值(空值)
Excel
在Excel中,可以根据查找->定位条件->空值快速定位数据中的空值,然后可以自己定义缺失值的填充方式,比如填充缺失值与之前的数据。
熊猫
在 pandas 中,可以使用 data.isnull().sum() 来检查缺失值,然后可以使用各种方法来填充或删除缺失值,例如我们可以使用 df = df.fillna(axis=0 ,method='ffill') 将缺失值水平/垂直替换为缺失值前面的值
重复数据删除
说明:重复值按指定要求处理
Excel
在Excel中,可以点击Data->Remove Duplicate Values按钮,选择需要去重的列。比如根据创建时间列对样本数据进行去重,可以发现去除了196个重复值,保留了629个唯一值。.
熊猫
在pandas中,可以使用drop_duplicates对数据进行去重,可以指定列和保留顺序,例如根据创建时间列对样本数据进行去重 df.drop_duplicates(['creation time'], inplace=True) ,可以发现与Excel处理的结果一致,保留了629个唯一值。
格式修改
说明:修改指定数据的格式
Excel
在Excel中可以选择需要转换的数据右键->修改单元格格式选择我们需要的格式
熊猫
在 Pandas 中没有固定的修改格式的方法。不同的数据格式有不同的修改方法。例如在Excel中修改创建时间为年月日,可以使用df['creation time'] = df['creation time'].dt.strftime('%Y-%m-%d' )
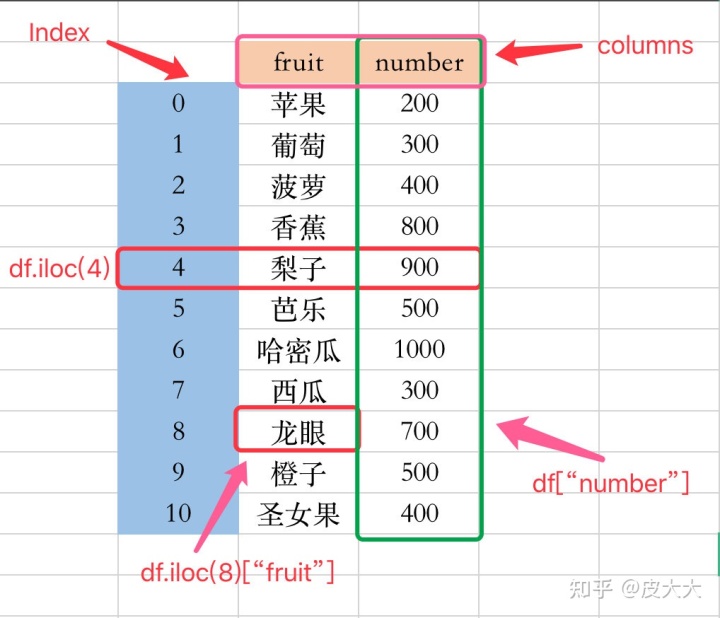
数据交换
说明:交换指定数据
Excel
在 Excel 中交换数据是一种非常常见的操作。以交换样本数据中的地址和位置两列为例。您可以选择地址列,按住 shift 键并将边缘拖动到下一列并释放它。
熊猫
pandas中交换两列的方式也有很多,比如交换样本数据中的address和position两列,可以通过修改列号来实现
数据合并
描述:将两列或多列数据合并为一列
Excel
在 Excel 中,您可以使用公式或 Ctrl+E 快捷键完成多列合并。以公式为例,合并样本数据中地址+位置列的步骤如下
熊猫
在 Pandas 中合并多列比较简单,和之前的数据插入操作类似,比如使用 df['merge column'] = df['address'] + df['post' 合并示例数据中的地址 + post 列]
数据拆分
说明:根据规则将一列拆分为多列
Excel
在Excel中,可以点击数据->列,根据提示选项设置相关参数完成列,但由于列中包含[]等特殊字符,需要先使用查找替换删除。
熊猫
在 Pandas 中,可以使用 .split 来补全列,但是在补全列之后,需要使用 merge 将分割后的数据添加到原来的 DataFrame 中。对于包含[]字符的分割数据,我们可以使用正则或者字符的字符串lstrip方法进行处理,但是因为不是pandas的特性,这里就不展开了。
数据包
描述:分组数据进行计算
Excel
在Excel中对数据进行分组,需要先对需要分组的字段进行排序,然后点击小计并设置相关参数即可完成,例如对样本数据的教育背景进行分组,求不同人的平均工资教育背景。
[外链图片传输失败有赞每日数据分析,源站可能有防盗链机制,建议保存图片直接上传(img-DfdJA1vg-1649206633925)()]
熊猫
使用 groupby 可以轻松地在 Pandas 中对数据进行分组。例如,使用 df.groupby("education").mean() 一行代码可以对样本数据的学历进行分组,求出不同学历的平均工资。结果与 Excel 相同。持续的
数据计算
描述:对数据做一些计算
Excel
Excel中有许多与计算相关的公式。例如,您可以使用 COUNTIFS 来统计 518 个薪水大于 10,000 的职位。
熊猫
在 Pandas 中,可以直接使用类似的数据过滤方法统计工资大于 10000 的职位数量 len(df[df[“salary level”]>10000])
统计数据
描述:对数据进行一些统计计算
Excel
Excel中有很多统计相关的公式,还有现成的分析工具,比如工资等级列的描述性统计分析,添加工具库后可以点击数据分析按钮,设置相关参数
熊猫
pandas中还有一个现成的describe函数,可以快速完成数据的描述性统计。例如,使用 df["salary level"].describe() 获取薪水列的描述性统计信息。
数据可视化
描述:可视化数据
Excel
在Excel中,可以通过点击Insert并选择一个图表来快速可视化数据,比如制作工资直方图,有很多样式可以直接使用
熊猫
Pandas 还支持直接在数据上绘制不同的可视化图表,比如直方图,可以使用 plot 或者直接使用 hist 制作 df["salary level"].hist()
数据采样
描述:根据需要对数据进行采样
Excel
Excel中的抽样可以使用分析工具库中的公式或抽样,但只支持数值列抽样,如样本数据中20个工资样本的随机抽样
熊猫
pandas中有采样功能sample,可以直接采样,支持任意格式的数据采样,可以按个数/比例进行采样,比如在样本数据中随机采样20个样本
数据透视表
说明:制作数据透视表
Excel
数据透视表是一个非常强大的工具。Excel中有现成的工具。只需要选中数据->点击插入->数据透视表即可生成,并且支持拖拽字段实现不同的数据透视表,非常方便。例如,制作地址、教育、工资的数据透视表
熊猫
在 Pandas 中制作数据透视表,可以使用 pivot_table 函数,例如制作地址、教育和工资的数据透视表 pd.pivot_table(df,index=["address","education"],values=["工资水平"]),虽然结果一样,但并不像 Excel 那样容易调整和多样化。
查找
说明:使用 VLOOKUP 查找数据
Excel
VLOOKUP是EXCEL中的核心功能之一,我们以一个简单的数据为例
熊猫
Pandas 中没有现成的 vlookup 功能,所以实现匹配查找需要一些步骤,首先我们看表
然后将数据框一分为二
最后修改索引,使用update来匹配两张表
结束语
以上就是使用 Pandas 演示如何在 Excel 中实现常用操作的全过程。其实可以发现,Excel的优势在于大部分数据处理都是通过交互点击完成的,而Pandas则完全依赖代码。对于数据透视表等一些操作,使用Excel来制作更方便,而一些数据分组、计算等操作,功能更强大,因为Pandas可以与NumPy等其他优秀的Python库相结合,所以我们处理数据时也需要正确选择使用的工具!


")



")

