
目录
数据预处理可视化数据剖析
在线社交网站为人们提供了一个建立社会关系网路和互动的平台。每一个人和组织都可以通过社交网站互动、获取信息并发出自己的声音,因此吸引了诸多的使用者。作为一个复杂的社会系统,在线社交网站真实地记录了社会网路的下降以及人类传播行为演变。通过抓取并剖析在线社交网站的数据,研究者可以迅速地掌握人类社交网路行为背后所隐藏的规律、机制乃至通常性的法则。
但是在线社交网路数据的获取方式有别于线下社会数据的获取(如普查、社会调查、实验、内容剖析等)、数据的规模常常十分大(称之为“大数据”并不为过)、跨越的时间范围也相对较长(与社会调查中的横截面数据相比),常规的数据剖析方式并不完全适用。比如传统的社会调查的数据常常样本量有限,而在线社交网路中的样本量可以达到千万甚至更多。因此,研究者急切得须要找寻新的数据获取、预处理和剖析的技巧。本章的内容具体包括数据的抓取、数据预处理、数据可视化和数据剖析部份。
Python本身的科学估算解释器发展也非常健全,比如NumPy、SciPy和matplotlib等。就社会网路剖析而言,igraph,networkx,graph-tool,Snap.py等泛型提供了丰富的网路剖析工具。
读者可以按照个人笔记本的操作系统安装相应的Python版本。目前最新的Python版本为3.0,而且一般使用者会选择使用更稳定的2.7版本。即使使用者也可以使用文本编辑器编撰代码,并且使用体验不如使用好的编译器。编译器是编撰程序的重要工具。目前,免费的Python编译器有Spyder、PyCharm(免费社区版)、Ipython、Vim、Emacs、Eclipse(加上PyDev插件)。对于使用Windows操作系统的用户,推荐使用Winpython。Winpython外置了Spyder为编译器,与Python(x,y)相比大小适中;免安装,下载后解压即可用;安装解释器很便捷,但是外置了NumPy、SciPy等泛型。
数据抓取
目前社交网站的公开数据好多,为研究者检验自己的理论模型提供了好多便利。诸如哈佛的社会网路剖析项目就分享了好多相关的数据集。社交网站为了自身的发展,常常也通过各类合作项目(比如腾讯的“犀牛鸟项目”)和大赛(比如Facebook通过Kaggle大赛公布部份数据)向研究者分享数据。
然而,有时侯研究者还是被迫须要自己搜集数据。受限于网站本身对于信息的保护和研究者自身的编程水平,互联网数据的抓取过程仍然存在诸多问题。以下,我们将从三个方面着手简略介绍使用Python进行数据抓取的问题:直接抓取数据、模拟登陆抓取数据、基于API插口抓取数据。
一、直接抓取数据
一般的数据抓取遵守可见即可得的规律,即可以观察到的,就可以被抓取。对于网页内容的抓取,可以是把整个网页都存出来,回头再清洗。这样做比较简单有效,而且还是回避不了以后的从html文件中进行的数据提取工作。在下边的事例当中,我们将尝试抓取百度新闻页面()的热点新闻。在这个事例当中,我们要使用urllib2这个例程来获取该网页的html文本。
在获取html以后,我们将使用一个流行的解释器BeautifulSoup来解析html并提取我们须要的信息。现今的BeautifulSoup早已发展到第四个版本。可以使用easy_install或则pipinstall的方式安装。假如读者使用的是Spyder的话,可以点击Tools--Opencommandprompt。之后,在打开的命令窗口中输入:easy_installbeautifulsoup4就可以了。
easy_install beautifulsoup4复制
使用beautifulsoup解析英文html的时侯遇见的主要问题多是由encoding引起的。须要使用sys设定默认的encoding形式为gbk,并在BeautifulSoup函数手指定from_encoding为gbk。
import urllib2from bs4 import BeautifulSoup#设置默认encoding方式import sysreload(sys)sys.setdefaultencoding('gbk')url = 'http://news.baidu.com/' #待抓取的网页地址content = urllib2.urlopen(url).read() #获取网页的html文本#使用BeautifulSoup解析htmlsoup = BeautifulSoup(content, from_encoding = 'gbk') #识别热点新闻hotNews = soup.find_all('div', {'class', 'hotnews'})[0].find_all('li')for i in hotNews:
print i.a.text #打印新闻标题
print i.a['href'] #打印新闻链接复制
这样就可以抓取当日的热点新闻,输出的结果如下:
习近平:改革惟其艰难 才更显勇毅http://china.cankaoxiaoxi.com/2014/0808/454139.shtml治疗费政府全担http://gb.cri.cn/42071/2014/08/06/2165s4643613.htm李克强点赞人物盘点:有女县长也有棒棒军http://news.youth.cn/jsxw/201408/t20140808_5605703.htm李克强指示地震救灾http://yn.yunnan.cn/html/2014-08/07/content_3316250.htm云南地震致615人遇难http://news.baidu.com/z/ynlddz/new/zhuanti.html临时安置点1顶帐篷内住20人http://news.youth.cn/gn/201408/t20140808_5607225.htm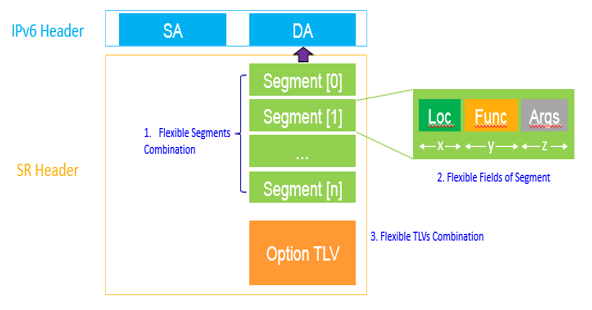
复制
二、模拟浏览器抓取数据
越来越多的网站要求必须登入能够听到内容,这个时侯就须要使用编程软件模拟浏览器登入。登陆成功后,就可以抓取内容了。这儿举一个抓取聊天峰会贴子列表的反例。这个网站的网路链接为:,我们首先写一个叫screen_login的函数。其核心是定义个浏览器对象br=mechanize.Browser()。这个时侯,须要借用浏览器的cookie功能,主要依靠于cookielib包。代码如下所示:(代码较多,请查看原文)
为了从HTML文档提取cookies,首先使用cookielib模块的LWPCookieJar()函数创建一个cookiejar的实例。LWPCookieJar()函数将返回一个对象,该对象可以从硬碟加载Cookie,同时能够向硬碟储存Cookie。以后,通过br.set_cookiejar(cj)将这个cookiejar关联到mechanize的浏览器对象br上。简单设置一些浏览器属性后,须要定义使用的user-agent。用户代理(UserAgent)指的是代表使用者行为的软件,主要是设置浏览器的头文件。
最后是关键的一步,打开登陆页面,输入用户名和用户密码。须要使用br.select_form(nr=0)来找到登陆表格。这儿nr的设置比较灵活,不同网站的数值不同。之后输入用户名和密码。诸如:br['vb_login_username']='YourregisteredUsername',这儿的vb_login_username也会随着网站本身使用的具体内容而不同。运行br=screen_login()就可以模拟登陆成功,之后就可以开始数据抓取和使用BeautifulSoup来进行信息提取的工作了,此处不再赘言。
三、基于API插口抓取数据
好在随着数字化媒体浪潮的到来,第三方开发的网站应用已然成为社交网路必不可少的一部份。社交网站为了自身的发展,常常选择向外界开放部份资源,以便捷第三方发展基于该社交网站的产品,从而更好吸引使用者使用。例如新浪微博上有着各类不同的APP,这种应用的数据插口(API)就是由新浪微博所提供的。
不同的编程语言与通用的API插口之间是由软件开发工具包SDK(SoftwareDevelopmentKit)衔接在一起的。一直以新浪微博的SDK为例,打开其页面()我们会发觉对应于各类编程语言的SDK,有些由新浪微博官方提供的,有些则是由广大使用者编撰的。就Python而言,新浪微博官方推荐的PythonSDK是sinaweibopy。sinaweibopy是纯Python编撰的单个文件,代码简约,无依赖,运行可靠。
安装sinaweibopy的方式十分简单,只须要打开的命令窗口中输入:easy_installsinaweibopy就可以了()。
easy_install sinaweibopy复制
数据抓取的第一步,就是构建数据联接的工作,以获取社交网站开放数据流的许可。其实,这首先须要使用者注册一个app。以新浪微博为例,研究者可到其应用开发页面注册。这样,使用者可以获取一个APP_KEY和对应的APP_SECRET。
现今流行的方法是使用OAuth获取联接社会化媒体的API的使用权限。它工作的原理十分简单:1.首先使用者发出使用恳求,2.之后新浪微博在收到恳求后向使用者发出一个授权码,3.获取授权码以后使用者根据授权码从新浪微博获取联接码(ACCESSTOKEN),4.使用联接码,使用者就可以联接到新浪微博的数据库并获取数据了。以上过程可以使用以下Python代码来实现:(代码较多,请查看原文)
在上述代码中,我们定义了一个名为weiboClient的函数。完成以上步骤以后,使用者只须要运行client=weiboClient()的程序,就可以联接到新浪微博的API插口了。
下一步是通过查阅社交网站的API文档,选定适当的API插口,就可以很便捷地从社交网站抓取数据了。由于直接从网站数据库获取数据,因此数据结构化较好。获取数据使用许可以后,其使用就十分便捷灵活了。2014年8月,四川汶川县发生大地震,人民晚报官方微博8月7日19:51来自人民晚报微博|举报发微博报导了最新的死亡人数。消息内容称:
人民晚报:#四川平武县水灾#【遇难人数增至615人[蜡烛]】据抗震赈灾指挥部消息,截止明天19时,水灾共导致615人死亡,其中雅安县526人、巧家县76人、昭阳区1人、会泽县12人;目前仍有114人失联,其中雅安县109人、巧家县5人;另有3143人重伤。
这儿须要注意的是每一条微博的号码有两种表示方式:一种是字母和数字的组合,另一种是数字。由该条微博的网路链接,我们可以得到后者为'Bhd8k0Jv8'。这个时侯,我们可以通过statuses__queryid这个API插口可以将它转化为纯数字的方式。其它更多的新浪微博API插口可以参阅%E6%96%87%E6%A1%A3_V2。
mid = client.get.statuses__queryid(mid = 'Bhd8k0Jv8', isBase62 = 1, type = 1)['id']复制
这儿,我们想要看一下这条微博的转发网路,并估算其网路特点。将主要用到的是API插口中的statuses__repost_timeline。在这个数据抓取过程中,每次可以抓取一个页面上的200条转发信息,依照总转发量,我们可以估算须要抓取的页面总量。由此,我们须要先定义一个函数,以确定转发页面的数目。如以下代码所示:(代码较多,请查看原文)
定义了以上函数以后,我们可以很容易地抓取并储存数据。代码如下:
client = weiboClient() #连接到API接口#定义存储文档地址dataFile = open("D:/github/weibo_repost/weibo_repost_all.csv",'wb') start = clock() #定义初始时间#使用for循环遍历所有的待抓取页面for page in range(1, pageNum + 1):
getReposts(mid, page) # 抓取单页的转发信息dataFile.close() # 关闭存储文件复制
数据预处理
大多数时侯,抓取的数据常常并不能直接满足我们剖析的需求,常常还须要对数据进行预处理。对于本章所涉及到的微博转发网路而言,主要是要理解二度转发的过程。如右图所示:
图1:二度转发和微博扩散网路
新浪微博不同与Twitter的一个地方在于,在一条微博的页面中记录了所有转发过这条微博的情况(除非被删掉)。如上图1-A中所示,我们用O来标识源微博,五个转发者分别是A、B、C、D、E。我们可以晓得就这条消息,五个转发者又被转发的次数。例如,B和D又分别被转发了2次和1次。我们把这些转发称之为二度转发(注意:二度转发这儿是一个十分自私的定义,它指的是源微博的转发者互相之间转发的情况)。二度转发可以用连边列表(edgelist)的方式表示并储存。在这个连边列表当中,第一列表示信息流出点,第二列表示信息流入点,如上图1-B所示。为此,通过抓取二度转发的情况,我们可以晓得信息流入点(这儿即C、D、E)都早已确定了其信息来源。只有未出现在二度转发第二列的点(即A、B)的信息来源不在信息转发者当中,这么其信息来源就只能是源微博O,如上图1-C所示,这样我们就可以补全二度转发的连边列表,如上图1-D所示。
基于以上信息,要想获取完整的转发网路,我们须要先获得二度转发网路。
#定义二度转发的函数def get2stepReposts(mid, uid, page): #将被二度转发的微博的mid和uid传递进来
try:
r = client.get.statuses__repost_timeline(id = mid, page = page, count = 200)
if len(r) == 0:
pass
else:
m = int(len(r['reposts']))
for i in range(0, m):
"""1.1 转发微博的属性"""
rt_mid = r['reposts'][i].id
created = r['reposts'][i].created_at
"""1.2 微博转发者的属性"""
user = r['reposts'][i].user
rt_uid = user.id
print >>dataFile2, "%s,%s,%s,%s,'%s'" % (mid, uid, rt_mid, rt_uid, created)
except Exception, e:
print >> sys.stderr, 'Encountered Exception:', e, page
time.sleep(120)
pass 复制
定义了抓取二步转发的函数以后,就可以抓取二步转发网路了。
with open("D:/github/weibo_repost/weibo_repost_all.csv") as f:
for line in f:
line = line.strip().split(',')
repostCount = int(line[3])
mid2step = line[0]
uid = line[7]
if repostCount > 0:
print mid2step, repostCount
if repostCount%200 == 0:
pages = repostCount/200
else:
pages = int(repostCount/200) + 1
dataFile2 = open("D:/github/weibo_repost/weibo_repost_2_step.csv",'a')
for page in range(1, pages + 1):
get2stepReposts(mid2step, uid, page)
dataFile2.close() 复制
在获取了二步转发数据以后,我们首先得到所有的转发者列表,之后获取二步转发网路中的信息流入节点,并对照两者的差别以找出直接从源微博转发的情况。
#首先得到所有的转发者列表with open("D:/github/weibo_repost/weibo_repost_all.csv") as f:
mids = []
for line in f:
line = line.strip().split(',')
mid = line[0]
mids.append(mid)#然后获取二步转发网络中的信息流入节点 with open("D:/github/weibo_repost/weibo_repost_2_step.csv") as f:
toNodes = []
for line in f:
line = line.strip().split(',')
mid = line[2]
toNodes.append(mid)#找到未出现在二步转发网络中的信息流入节点的转发者 oneStep = [] for i in mids:
if i not in toNodes:
oneStep.append(i)#构建一步转发数据with open("D:/github/weibo_repost/weibo_repost_all.csv") as f:
for line in f:
line = line.strip().split(',')
created = line[1]
mid = line[0]
uid = line[7]
rtmid = line[18]
rtuid= line[20]
if mid in oneStep:
with open('D:/github/weibo_repost/weibo_repost_1_step.csv', 'a') as g:
record = rtmid + ','+ rtuid+','+ mid + ','+uid+','+created
g.write(record+"\n")#合并一步转发和二步转发,得到完整的转发网络。with open("D:/github/weibo_repost/weibo_repost_1_step.csv") as f:
for line in f:
with open('D:/github/weibo_repost/weibo_reposts_network.csv', 'a') as g:
g.write(line)with open("D:/github/weibo_repost/weibo_repost_2_step.csv") as f:
for line in f:
with open('D:/github/weibo_repost/weibo_reposts_network.csv', 'a') as g:
g.write(line)复制
到这儿,我们就得到了完整的转发网路。
可视化
为了彰显时间的先后次序,我们首先提取转发网路中的转发时间
# 首先,提取转发时间信息with open('D:/github/weibo_repost/weibo_repost_network.csv', 'r') as f:
rt_time = []
for line in f:
time= line.strip().split(',')[-1]
day = time[7:9]
hms= time[9:17].replace(':', '')
time = int(day + hms)
rt_time.append(time)
#计算转发时间的先后顺序import numpyarray = numpy.array(rt_time)order = array.argsort()ranks = order.argsort()复制
之后我们可以重构转发网路。
# 构建微博转发网络 import matplotlib.pyplot as pltimport networkx as nx G = nx.Graph()with open('D:/github/weibo_repost/weibo_repost_network.csv', 'r') as f:
for position, line in enumerate(f):
mid, uid, rtmid, rtuid= line.strip().split(',')[:-1]
G.add_edge(uid, rtuid, time = ranks[position])edges,colors = zip(*nx.get_edge_attributes(G,'time').items())degree=G.out_degree()#计算节点的出度path_length = nx.all_pairs_shortest_path_length(G)depth =[ path_length['2803301701'][i] for i in degree.keys()]pos=nx.spring_layout(G) #设置网络的布局fig = plt.figure(figsize=(10, 8),facecolor='white')nx.draw(G, pos, nodelist = degree.keys(),
node_size = [np.sqrt(v+1)*10 for v in (degree.values())], node_color = depth,
node_shape = 'o', cmap=plt.cm.gray,
edgelist = edges, edge_color = 'gray', width = 0.5,
with_labels = False, arrows = False)plt.show()复制
图2:人民晚报所发的#四川青川县水灾#微博的转发网路
很其实人民晚报的这条微博的转发具有显著的星形扩散的特点:与通过社交网路的传播相比,这条微博具有显著的媒体传播特点,即以人民晚报作为核心,信息多数是由人民晚报直接抵达用户,而不须要经过其它用户的中转。
两步流动理论强调信息首先由媒体传递到意见领袖,而后由电邮领袖传播到广大的受众。因而它指出了不仅媒体意外,社会网路中的意见领袖对于信息扩散也发挥着重要作用(Lazarsfeld,Berelson,Gaudet,1944;Katz,E.,1957)。并且,通过这个案例,我们发觉并非这么。我们可以觉得似乎人民晚报官方微博承载在社交网路当中,而且其传播方法仍然保持了传播媒体信息的一步抵达受众的特征(其实这些特点比线下更强)。
数据剖析
对于网路数据的剖析,首先是一些网路的统计指标。按照剖析的单位分为网路属性、节点属性和传播属性。其中网路属性包括网路的规模,网路群聚系数,半径和平均距离,匹配性;节点属性包括节点间的距离,中心性等方面;而传播的属性则关注传播的时空和网路特点。
节点属性
就节点的属性而言,我们首先关注节点间的距离。检测了一个节点到网路中所有的其它节点之间的距离,其中最大的距离就是这个节点的离心度(eccentricity)。网路的直径(radius)就是最小的节点离心度;网路的半径(diameter)就是最大的节点离心度。不过,离心度的估算须要将有向网路转化为无向网路。经过估算,该信息转发网路的半径是4,直径是2。
另外,我们可以使用nx.all_pairs_shortest_path_length(G)函数估算任意一对节点之间的路径宽度。我们晓得源微博的发出者是'2803301701'(即@人民晚报)。我们选定另外一个节点'1783628693'。使用nx.shortest_path来估算两个节点之间的路径。发觉节点'1783628693'经过'1904107133'转发源微博,也就是说节点'1783628693'和源微博之间的距离是2。我们还可以估算网路的平均最短距离,发觉该有向网路的平均最短路径很小,只有0.001;但若果把网路转化为无向网路,其平均最短路径就小于2了。
UG=G.to_undirected()eccen = nx.eccentricity(UG)#节点离心度max(eccen.values() #4min(eccen.values() #2nx.diameter(G) # 网络直径4nx.radius(G) #网络半径2path = nx.all_pairs_shortest_path(G)nx.shortest_path(G, source = '2803301701', target ='1783628693' )#['2803301701', '1904107133', '1783628693']nx.shortest_path_length(G, source = '2803301701', target ='1783628693' ) #2nx.average_shortest_path_length(G) # 网络平均最短距离0.001nx.average_shortest_path_length(UG) # 网络平均最短距离2.05复制
另外一个方面,我们关心节点的中心程度。常用的度量包括:节点的度(degree)、接近度(closeness)、中间度(betweenness)。
degree = nx.degree(G)closenesss = nx.closeness_centrality(G)betweenness = nx.betweenness_centrality(G)复制
对于网路研究而言,一个很重要的方面是关注网路的度分布。现实生活中的大多数网路节点的度具有较强的异质性,即有的节点的度很大,而多数节点的度很小。我们可以画出双对数座标下的网路度分布以及网路度-排行分布。
degree_hist = nx.degree_histogram(G)x = range(len(degree_hist))y = [i / int(sum(degree_hist)) for i in degree_hist]plt.loglog(x, y, color = 'blue', linewidth = 2, marker = 'o')plt.title('Degree Distribution')plt.ylabel('Probability')plt.xlabel('Degree')plt.show()复制
图2:网路度分布
# 绘制网络度排名的概率分布图from collections import defaultdictimport scipy.stats as ssd = sorted(degree.values(), reverse = True )d_table = defaultdict(int)for k in d:
d_table[k] += 1d_value = sorted(d_table)d_freq = [d_table[i] for i in d_value]d_prob = [i/sum(d_freq) for i in d_freq]d_rank = ss.rankdata(d_value).astype(int)plt.loglog(d_rank, d_prob, color = 'blue', linewidth = 2, marker = 'o')plt.title('Degree Rank-order Distribution')plt.ylabel('Probability')plt.xlabel('Rank')plt.show()复制
图2:网路度排行机率分布图
网路属性
网路层级的属性使用networkx特别容易估算。按照估算我们发觉在这个完整的转发网路当中,共有1047个节点和1508个链接。由此,也可以晓得网路的密度(实际存在的链接数目和给定节点的数目可能存在链接数目之间的比值)较小,经过估算只有0.001左右。使用nx.info()函数也可以给出网路节点数目和链接数目。
假如说网路密度关注的是网路中的链接,传递性(transitivity)关注的则是网路中的三角形的数目,传递性也因而被定义为存在的三角形数目与三元组的数目的比值再除以3(由于一个三角形构成三个未闭合的三元组)。经过估算发觉网路传递性的数值是0.001,也特别小,这说明网路中闭合的三角形十分少。
按照节点所在的闭合三角形的数目,还可以估算节点的群聚系数。我们晓得,对于没有权重的网路而言,节点的度(D)越高,可能占有的三角形数目(\frac{D(D-1)}{2})就越高。节点的群聚系数就是节点占有的闭合三角形的数目和可能占有的三角形数目之间的比值。使用nx.triangles(G)函数可以估算出每位节点所占有的三角形数目,结合节点的度,就可以估算出节点的群聚系数。其实了,节点群聚系数可以直接使用nx.clustering(G)得到。估算所有网路节点的群聚系数,取其平均值就是网路的群聚系数。经过估算网路的群聚系数为0.227。其实了,网路群聚系数可以直接使用nx.average_clustering(G)函数得到。另外的一个网路统计指标是匹配性。经过估算,网路节点度的匹配性为负值,即度小的节点多与度大的节点相连。
G.number_of_nodes() # 节点数量1047 G.number_of_edges() # 链接数量1508nx.density(G) # 网络密度0.001nx.info(G)#'Name: \nType: DiGraph\nNumber of nodes: 1047\nNumber of edges: 1518\nAverage in degree: 1.4499\nAverage out degree: 1.4499'nx.transitivity(G) # 传递性0.001nx.average_clustering(UG) # 网络群聚系数0.227nx.degree_assortativity_coefficient(UG) # 匹配性-0.668复制
传播属性扩散深度
转发者距离原微博发出者的距离可以看做是该条信息转发被中介化的程度。我们早已晓得,离心度评判的是一个节点到其它所有节点距离中的最大值。假如我们检测源微博发出者(@人民晚报)的离心度,我们就可以找到这个转发网路的信息扩散深度(diffusiondepth)。不难算出,其扩散深度是2。由此可见尽管转发过百人,并且这些扩散主要是广度优先的扩散,其扩散的深度却十分有限。
eccen = nx.eccentricity(UG) #节点离心度eccen['2803301701'] #深度为2, '2803301701'即@人民日报#找到扩散深度最大的节点path_length = nx.all_pairs_shortest_path_length(G)oPath = path_length['2803301701']maxDepth = filter(lambda x: oPath[x] == max(oPath.values()), oPath.keys())len(maxDepth) # 扩散深度最大的节点数量29复制
扩散速率
from datetime import datetimewith open('D:/github/weibo_repost/weibo_repost_network.csv', 'r') as f:
rt_time = []
for line in f:
time= line.strip().split(',')[-1]
day = time[7:9]
hms= time[9:17].replace(':', '')
time = int(day + hms)
rt_time.append(time)day = [('2014-08-0'+str(i)[:1]+'-'+str(i)[1:3]) for i in rt_time]day = [datetime.strptime(d, '%Y-%m-%d-%H') for d in day]day_weibo = datetime.strptime('2014-08-07-19', '%Y-%m-%d-%H') #源微博发出时间hours = [(i-day_weibo).total_seconds()/3600 for i in day]values, base = np.histogram(hours, bins = 40)cumulative = np.cumsum(values)plt.subplot(1, 2, 1)plt.plot(base[:-1], cumulative, c = 'red')plt.title('Cumulative Diffusion')plt.ylabel('Number of Retweets')plt.xlabel('Hours')plt.subplot(1, 2, 2 )plt.plot(base[:-1], values, c = 'orange')plt.title('Hourly Diffusion')plt.xlabel('Hours')plt.show()复制
图:微博转发时间分布
源微博发表于2014年8月7日下午19点,我们统计每一条转发微博的时间与源微博时间的时间差(以小时为单位),结果如上图所示。第一波主要的转发就在源微博发出不久(前5个小时),然后的微博转发速率增加;第二波转发是第二天早晨10点左右(第15个小时左右),并且其幅度很低,而且很快增加了。这些模式反应了公众注意力投放的规律,即由于公众注意力有限,所以信息的扩散具有很强的时间限制。以这个微博转发的案例为例,五个小时后,累计下降曲线就开始显得平坦,虽然到了第二天早上这些状态也没有得到改变。
空间分布
据悉,我们可以剖析转发者的地理分布情况。我们须要提取微博转发者的省份信息。这儿还须要新浪微博省市的地理编码。见这儿:%E7%9C%81%E4%BB%BD%E5%9F%8E%E5%B8%82%E7%BC%96%E7%A0%81%E8%A1%A8。将这个列表整理为一行代表一个省区的方式,并命名为weibo_province.txt。按照这个地理编码的列表,我们可以将省份编码转化为省份的名称。以后,我们就可以统计各个省区的微博转发数目,并勾画地理分布的直方图。
from collections import defaultdictfrom matplotlib.font_manager import FontPropertiesimport numpy as np#提取微博转发者的省份信息with open("D:/github/weibo_repost/weibo_repost_all.csv") as f:
province = dict()
for line in f:
line = line.strip().split(',')
uid = line[7]
province[uid] = line[9]#读取省份代码列表with open("D:/github/weibo_repost/weibo_province.txt") as f:
province_dict = dict()
for line in f:
pid = line.split('\t')[0]
provinceName = line.split('\t')[1].split(',')[0]
province_dict[pid] = provinceName#获取省份名称 province_info = [province_dict[i] for i in province.values()]#获取各个省份的微博转发数量province_table = defaultdict(int)for k in province_info:
province_table[k] += 1#根据微博转发数量对省份名称排序 province_table_sorted = sorted([(value, key) for (key, value) in province_table.items()])#获取排序后的省份微博转发数量和对应的省份名称 provinceFreq= [i[0] for i in province_table_sorted]provinceName = [unicode(i[1]) for i in province_table_sorted]#绘制直方图position = np.arange(len(provinceName))ax = plt.axes()ax.set_xticks(position +0.5)font = FontProperties(fname = r'c:\windows\fonts\simsun.ttc', size = 10)ax.set_xticklabels(provinceName, fontproperties = font)plt.bar(position, provinceFreq)plt.show()复制
图:微博转发数目的省区分布
由该省区分布可以晓得,广州,上海,江苏,浙江是转发量最多的四个省份,而新疆、新疆、西藏、宁夏等东部省份和港澳台等地的转发最少。由于风波的地域相关性,河南省的转发数目也相对较多。
结语
综上所述,本章简单描绘了使用Python抓取、预处理、分析、可视化社交网路数据的过程。主要以案例为主,其中又以描摹新浪微博单条信息的扩散为主。就数据抓取而言,社会化媒体提供了异常丰富的内容,因而本文所举得反例很容易就可以扩充到更多的案例、更长的时间、更多的网站。可以参阅Russell(2011;2013)在《MiningtheSocialWeb》和《21RecipesforMiningTwitter》两书中所提供的更多的反例。
就网路剖析而言,本文仅仅介绍了一些最基本的剖析方式和Python的实现方式,尤其是networkx的使用。值得一提的是,不仅Python,还有好多其它的选择,例如R软件;不仅networkx之外,还有igraph、graph-tool、Snap.py等其它泛型。就囊括的内容而言,限于篇幅,同样有一些内容没有被涵盖进来,例如网路的生成、网络社区的界定、信息扩散的模拟。
不可证实的是,读者不可能通过本章完全把握Python的使用、数据的抓取和社交网路研究的剖析方式。本书附表中总结了一些常用的资源和工具(软件、类库、书籍等)。读者可依照自己的偏好和研究目的,按图索骥,通过不断地动手练习来达到持续进步的目的。








